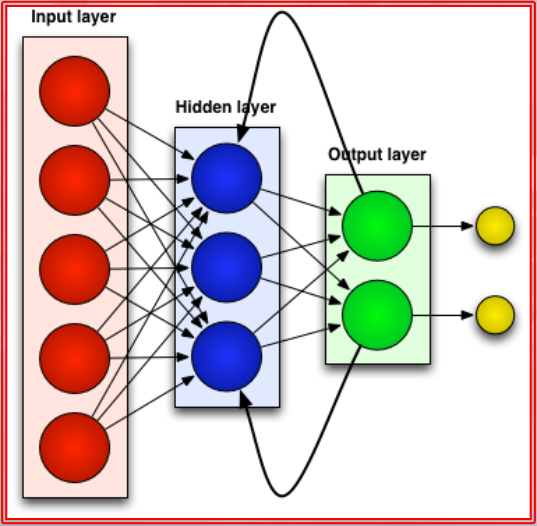
==Temporal dynamic neural networks are a type of artificial neural network that is designed to model sequential or time-dependent data. They are also known as recurrent neural networks (RNNs) and are a type of dynamic neural network that can adapt their architecture based on the input data==.
RNNs are particularly useful in applications where the input data has a temporal relationship, such as speech recognition, natural language processing, and stock market prediction. Unlike static neural networks, RNNs can take into account the previous inputs and their corresponding outputs while processing new inputs. This allows them to capture long-term dependencies in the input data and produce more accurate predictions.
The architecture of an RNN typically includes a hidden state that is updated at each time step based on the current input and the previous hidden state. The updated hidden state is then used to make a prediction or generate an output. This process is repeated for each time step in the sequence.
==One limitation of traditional RNNs is that they can suffer from the vanishing gradient problem==, where the gradients of the network become very small during training and prevent the network from learning long-term dependencies. To address this issue, several variants of RNNs have been developed, including long short-term memory (LSTM) and gated recurrent unit (GRU) networks. These variants incorporate additional mechanisms to help the network remember and forget information over longer time periods, making them more effective at modeling sequential data.
What are the Differences between Partially Recurrent and Recurrent Networks?
Partially recurrent networks (PRNs) and recurrent networks (RNNs) are both types of neural networks that are commonly used for processing sequential data. However, there are some key differences between these two types of networks.
Network architecture: The main difference between PRNs and RNNs is in their network architecture. PRNs have a feedforward network structure with connections that skip some layers, whereas RNNs have a feedback loop that allows information to be passed from one time step to the next.
Information flow: In PRNs, information flows from one layer to the next in a feedforward manner, with some layers skipping other layers. In RNNs, information flows from one time step to the next through the feedback loop.
Memory: RNNs are designed to have memory, which means that they can remember previous inputs and use that information to make predictions about future inputs. PRNs, on the other hand, are not explicitly designed to have memory and may not be able to make use of past inputs in the same way.
Training: The training of PRNs is generally easier and more stable than RNNs. This is because PRNs have a simpler architecture and are less prone to the vanishing or exploding gradient problem that can occur in RNNs.
Applications: PRNs are often used for tasks that require processing of long sequences of data, such as speech recognition and natural language processing. RNNs are also used in these applications, but they are also commonly used in other tasks, such as image captioning and stock price prediction.
In summary, while PRNs and RNNs share some similarities in their ability to process sequential data, their network architecture, information flow, memory, training, and applications can differ significantly. Choosing the right type of network depends on the specific task at hand and the properties of the data being processed.
What are State or Context Units?
==State or context units are a type of neuron or node found in recurrent neural networks (RNNs) that serve as a memory mechanism==. ==These units are responsible for storing information about the previous inputs or context of the network, and can then use this information to inform the processing of future inputs==.
In an RNN, each input is processed in sequence, with the output of each processing step fed back into the network as an input for the next step. This creates a feedback loop that allows the network to maintain a memory of the previous inputs. The state or context units are responsible for capturing this context and passing it on to the next processing step.
The specific function of state or context units can vary depending on the type of RNN and the application for which it is being used. In some cases, these units may simply store the previous input in a fixed-size memory buffer. In other cases, more sophisticated memory mechanisms may be employed, such as long short-term memory (LSTM) or gated recurrent unit (GRU) cells, which are designed to selectively retain and forget information based on the current input.
Overall, state or context units are a critical component of recurrent neural networks, allowing them to process sequential data and maintain a memory of the previous inputs. By using this memory to inform the processing of future inputs, RNNs can achieve state-of-the-art performance on a wide range of tasks, including natural language processing, speech recognition, and time series prediction.
—————————————————————
Slides with Notes
What are the State or Context Units?
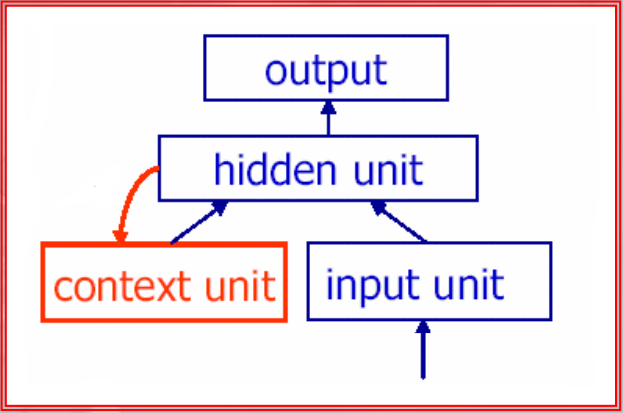
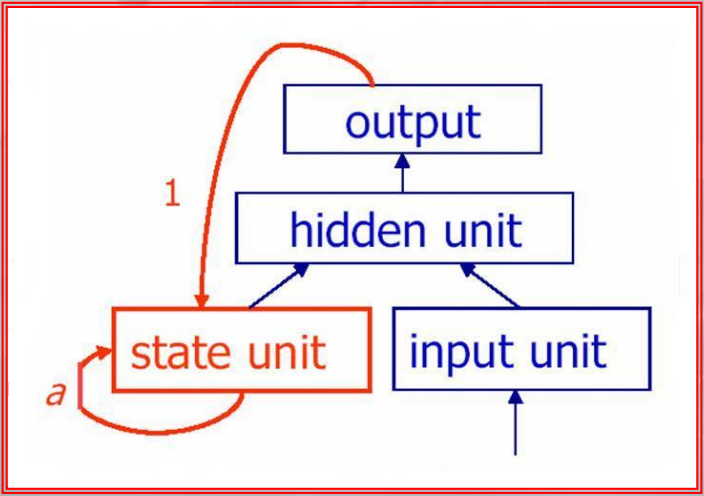
We are referring to the layer with a feedback loop, the state units are the one that send their output to the next feedforward iteration as input to another layer.
~Example: In this image the state units are the units in the output layer
Also remember that state or context units do not need to occupy an entire layer, as we can see in this example:
Is there a Difference between State and Context Units?
NO, the names can be interchanged
~Example: Context Unit, note that there is NO self-loop:
~Example: Context Unit, note that there is a self-loop: