Questions
- What is Hierarchical Clustering?
- Hierarchical clustering is a clustering algorithm used in data analysis and data mining.
The goal of hierarchical clustering is to group similar data points into clusters based on a similarity metric.
The algorithm starts with each data point in its own cluster and then proceeds iteratively to merge pairs of clusters until a stopping criterion is met. - There are two main types of hierarchical clustering: agglomerative and divisive.
- ==Agglomerative hierarchical clustering is a bottom-up approach, where each data point starts in its own cluster and pairs of clusters are iteratively merged until all points are in a single cluster==.
- ==Divisive hierarchical clustering is a top-down approach, where all data points start in a single cluster and the algorithm recursively splits the data into smaller clusters==.
- Hierarchical clustering produces a dendrogram, which is a tree-like diagram that shows the relationships between the clusters.
The dendrogram can be used to visualize the clustering results and to choose the appropriate number of clusters for downstream analysis.
- Hierarchical clustering is a clustering algorithm used in data analysis and data mining.
- What is Agglomerative Hierarchical Clustering?
- Agglomerative hierarchical clustering is a type of clustering algorithm used in unsupervised machine learning to group similar items or data points together. In this method, each item or data point is initially considered as an individual cluster. The algorithm then starts merging these clusters based on the similarity between them. The process of merging continues until all the items are grouped into a single cluster.
- Agglomerative hierarchical clustering uses a bottom-up approach, where the algorithm starts with individual data points and then merges them iteratively. The similarity between two clusters is measured using a distance metric, such as Euclidean distance or Manhattan distance. The algorithm then merges the two closest clusters based on the distance metric.
- The agglomerative hierarchical clustering algorithm generates a dendrogram, which is a tree-like diagram that represents the clustering process. The dendrogram starts with individual data points at the bottom, and each subsequent level represents the merging of two clusters at the previous level. The height of each level in the dendrogram represents the similarity between the merged clusters. The branches in the dendrogram represent the clusters, and the leaves represent the individual data points.
- Agglomerative hierarchical clustering is useful in exploratory data analysis, pattern recognition, and image segmentation, among other applications.
—————————————————————
IMPORTANTE
IMPORTANTE Hierarchical clustering: Un modo poco dispendioso per organizzare geni, o più in generale creare alberi filogenetici, è quello di utilizzare algoritmi di clustering, partendo con foglie le raggruppiamo due a due, una volta create un “cluster” di due foglie al suo posto ne mettiano una sola la cui “distanza” è media alle due unite. L’algoritmo di cluster ha complessità dove è il numero di foglie
—————————————————————
Slides with Notes


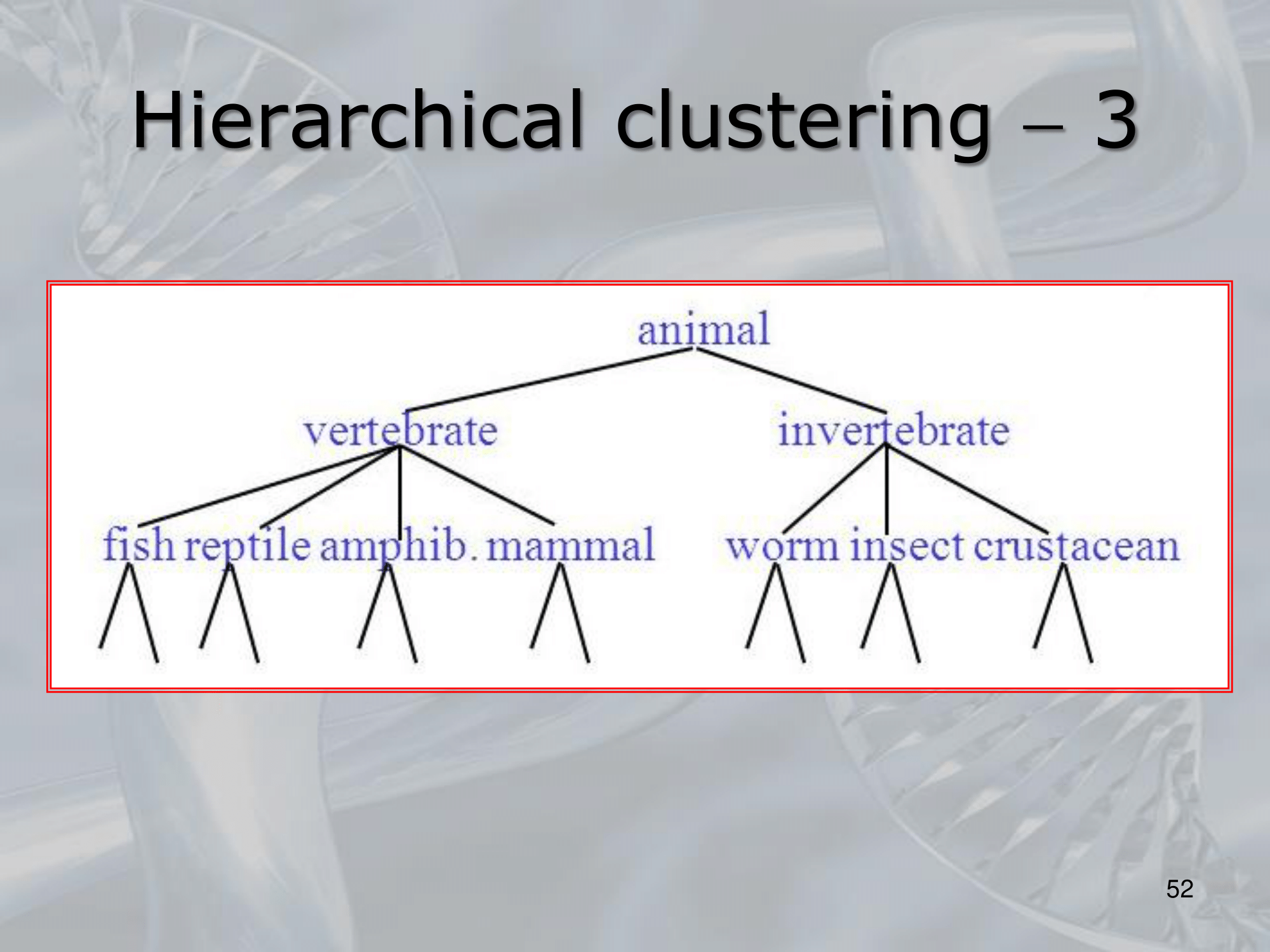

IMPORTANTE Hierarchical clustering: Un modo poco dispendioso per organizzare geni, o più in generale creare alberi filogenetici, è quello di utilizzare algoritmi di clustering, partendo con foglie le raggruppiamo due a due, una volta create un “cluster” di due foglie al suo posto ne mettiano una sola la cui “distanza” è media alle due unite. L’algoritmo di cluster ha complessità dove è il numero di foglie