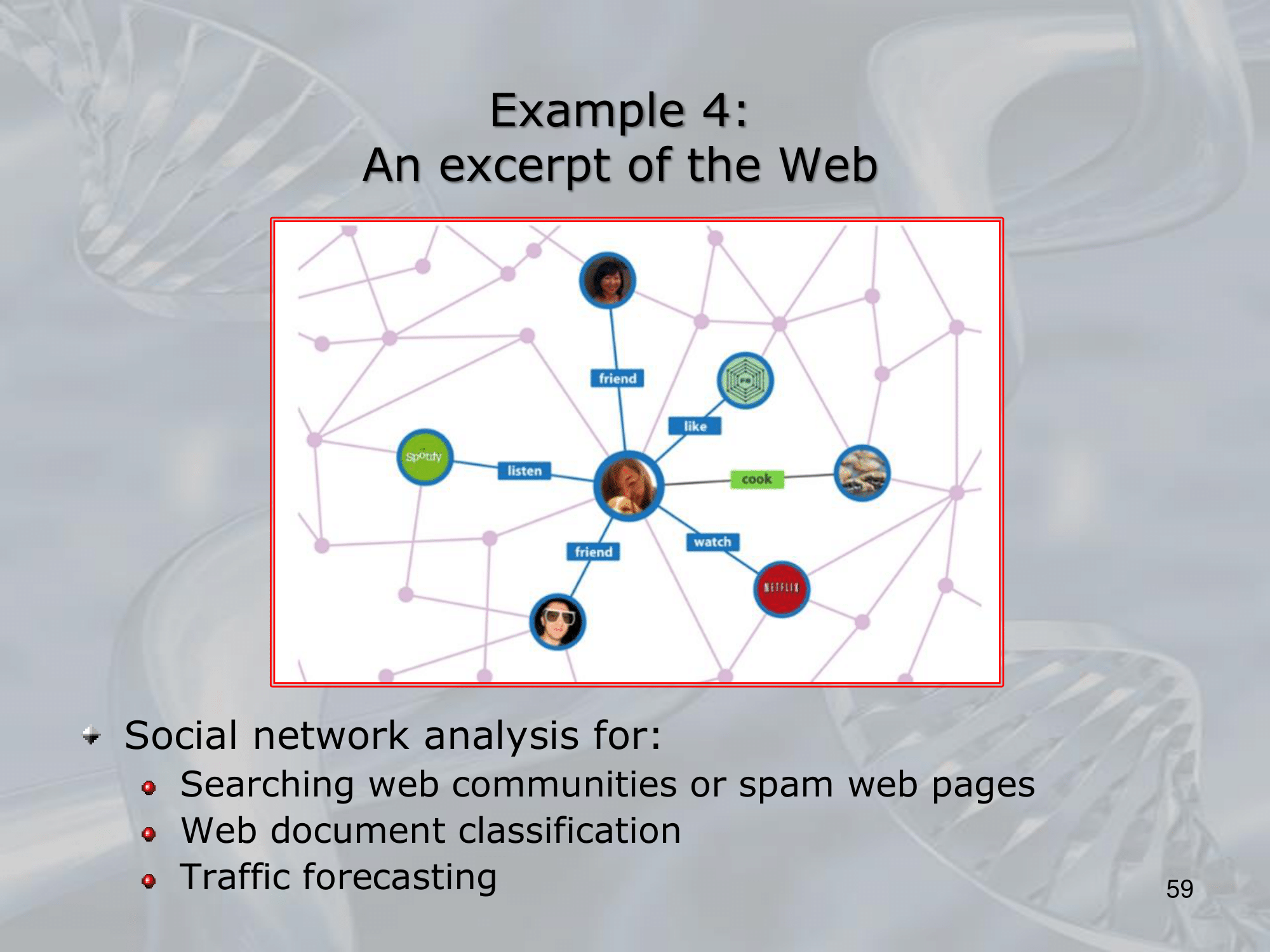
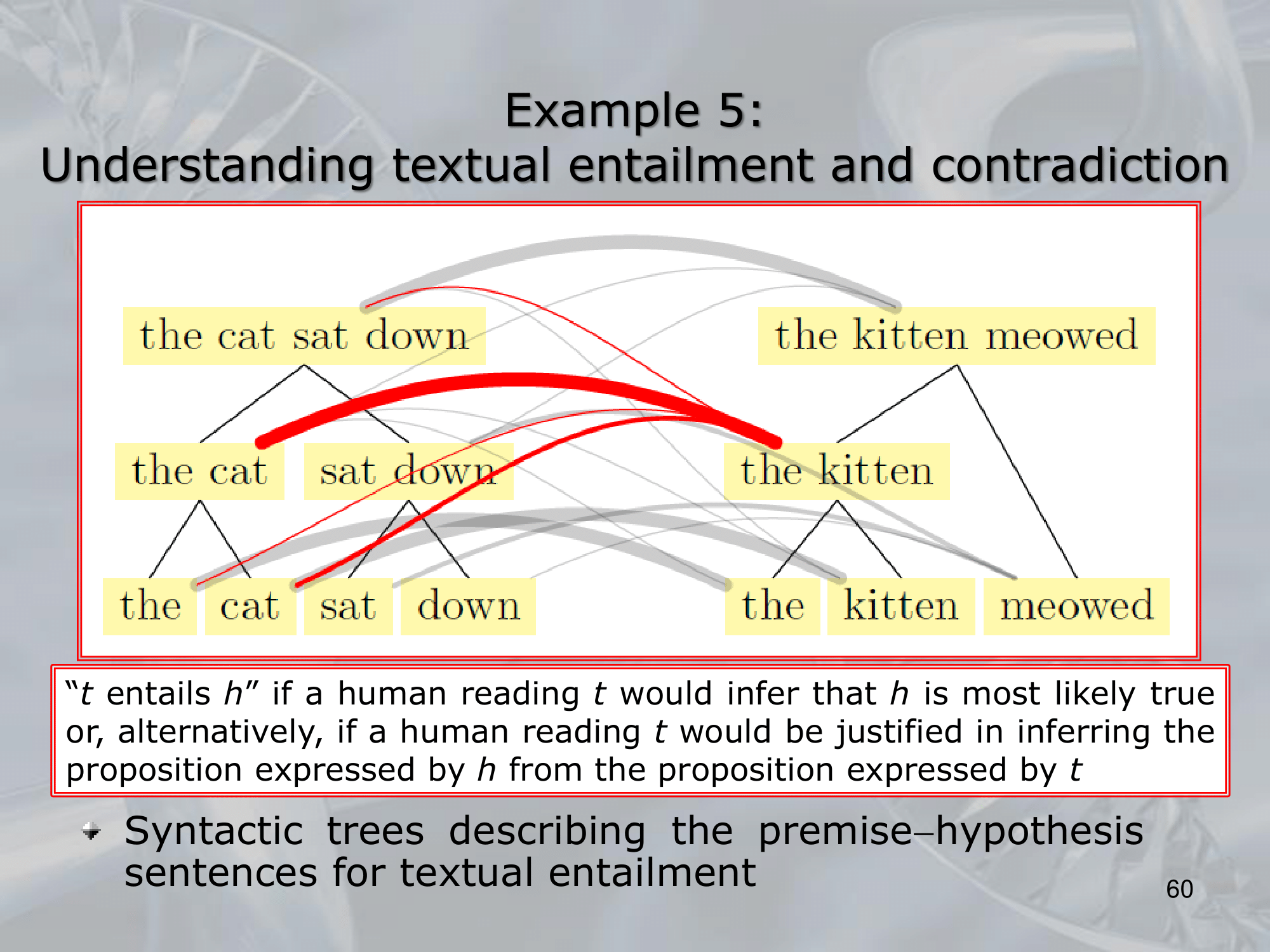
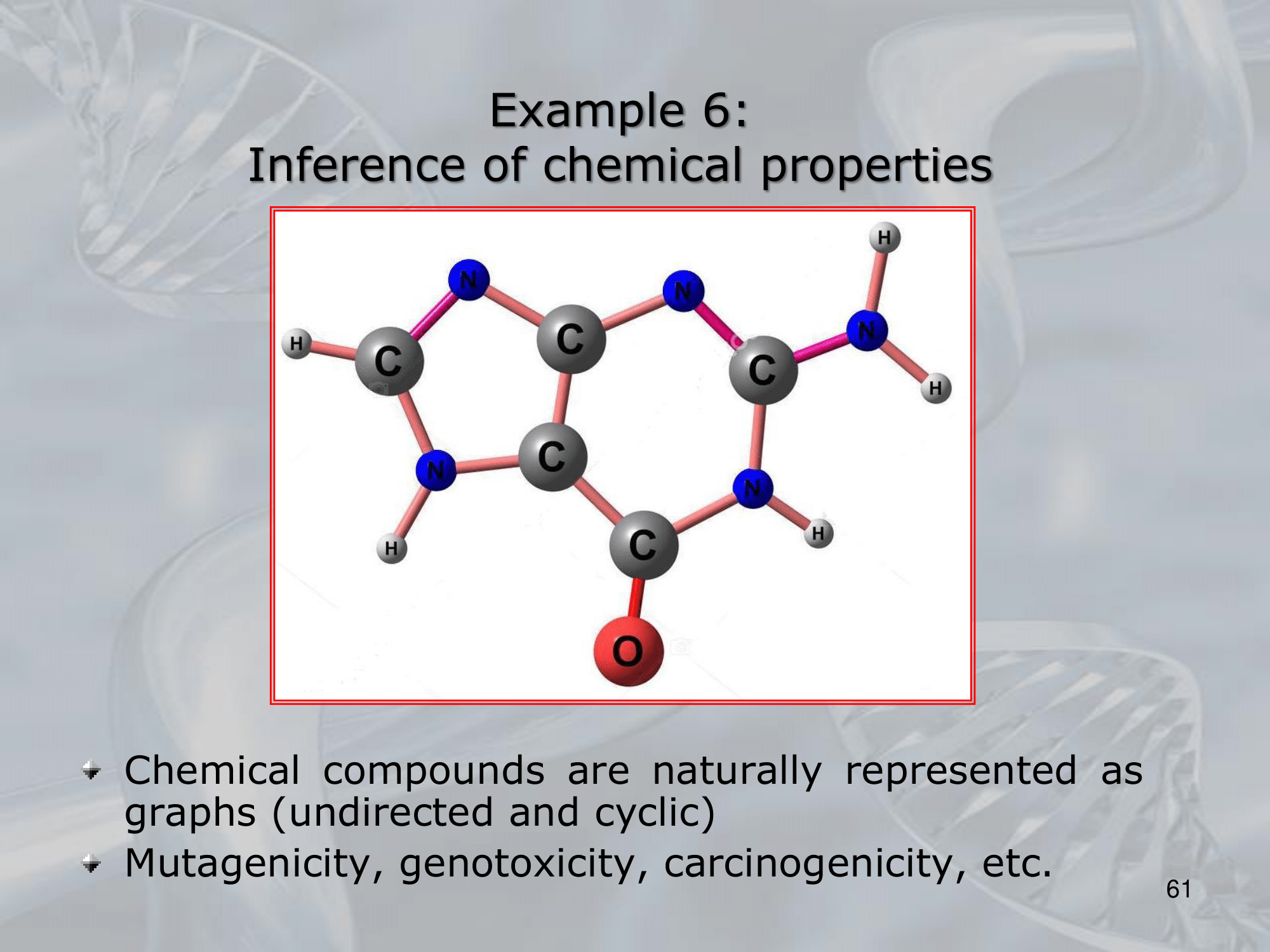
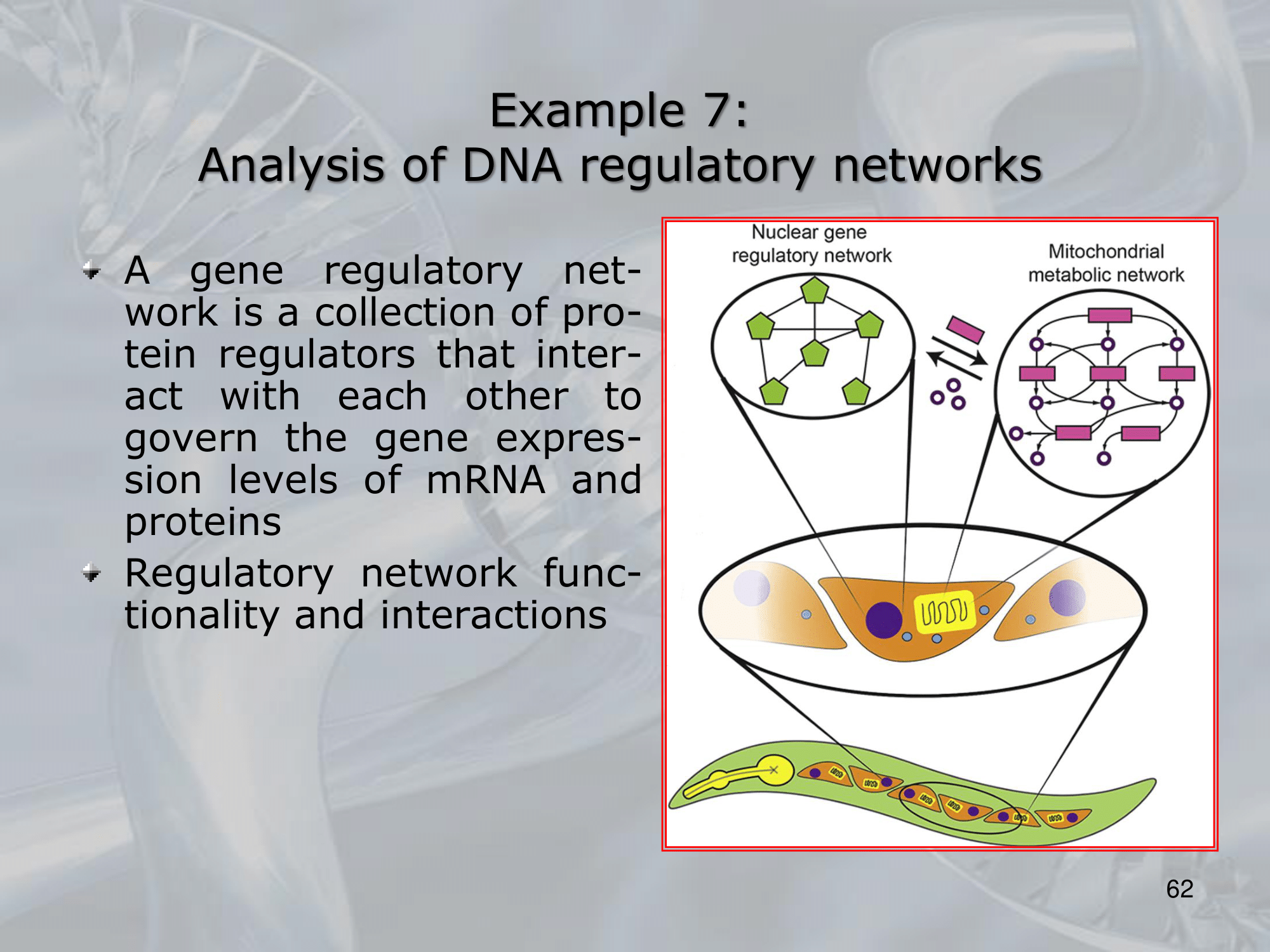
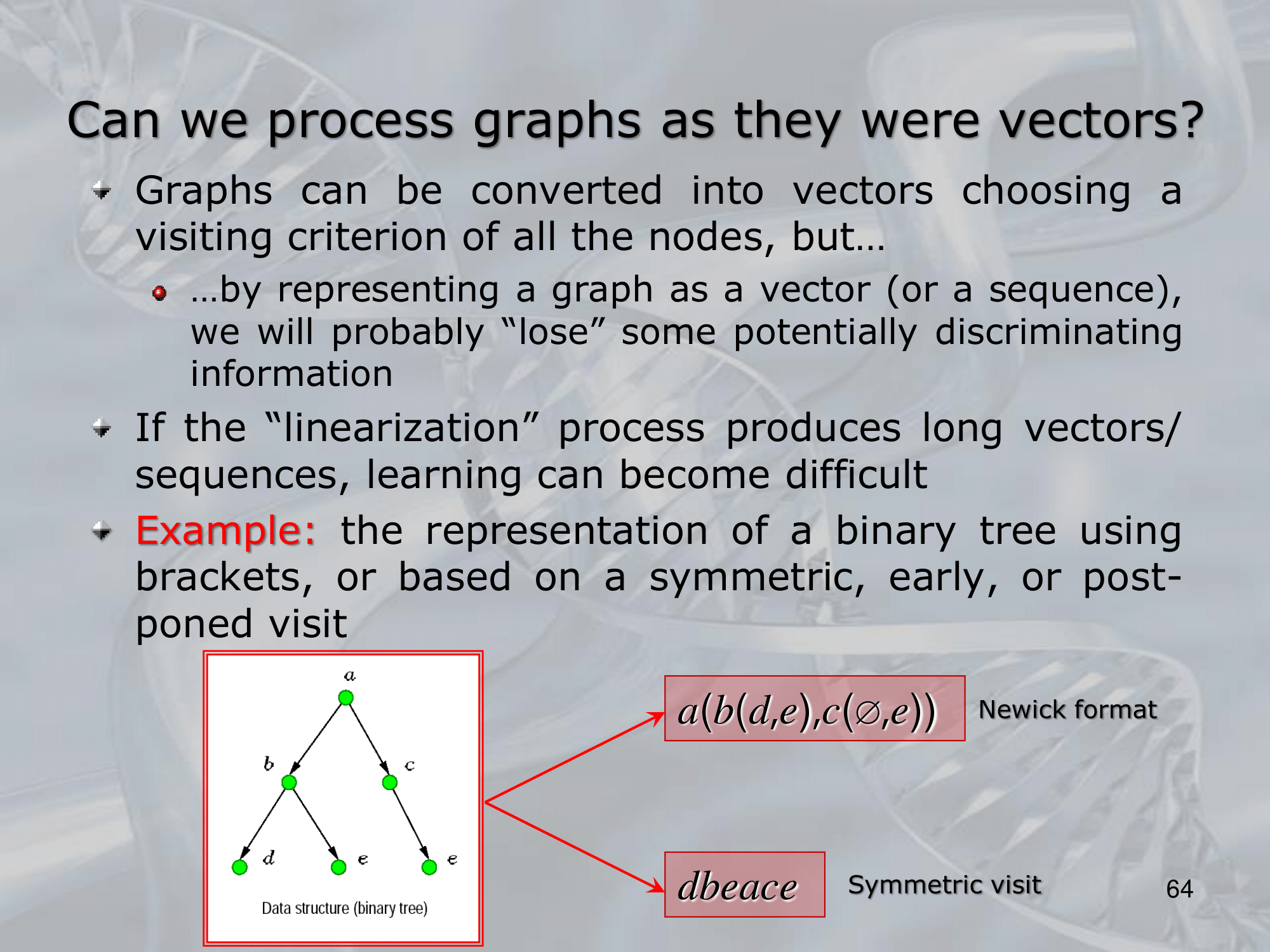
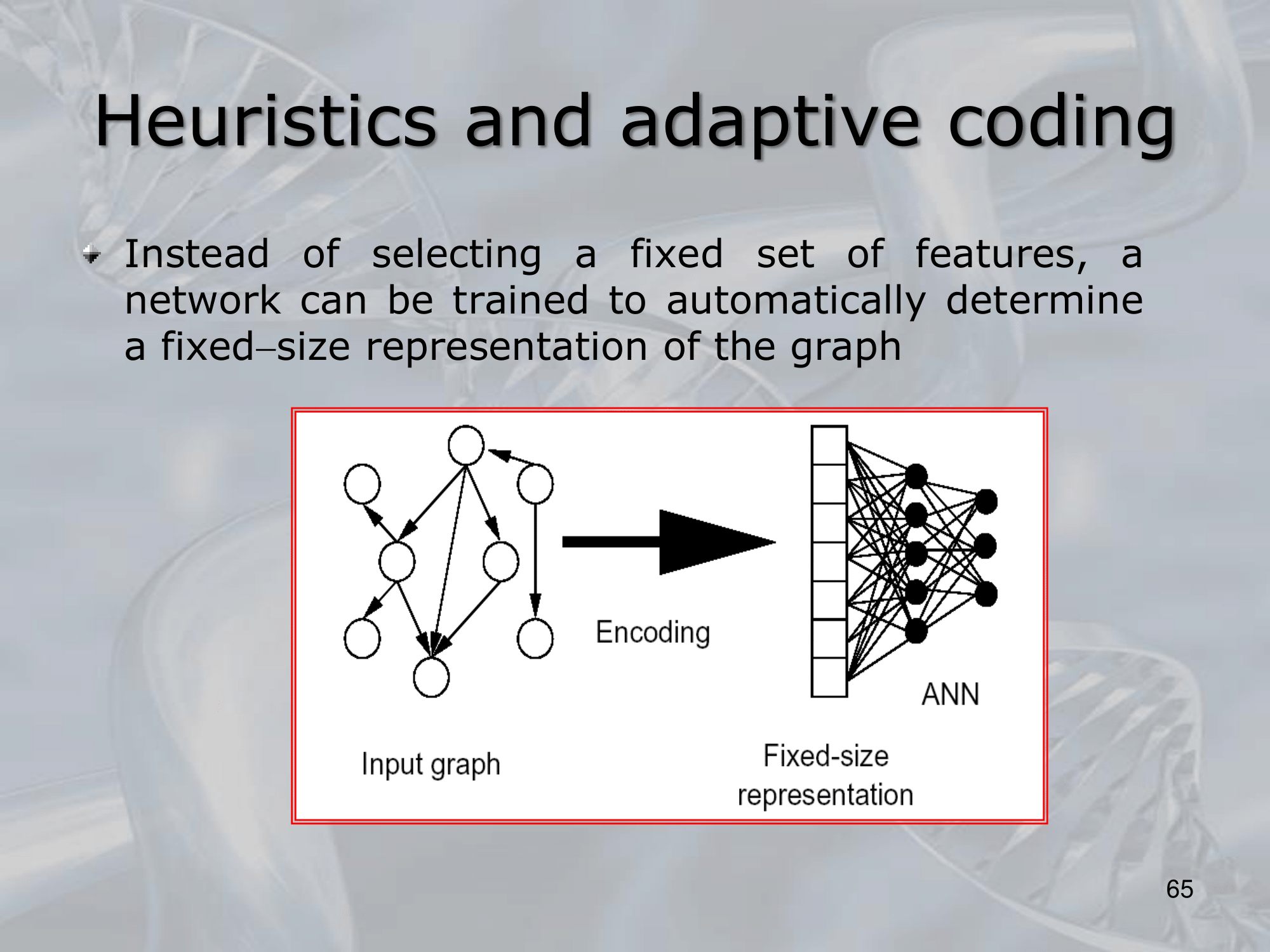
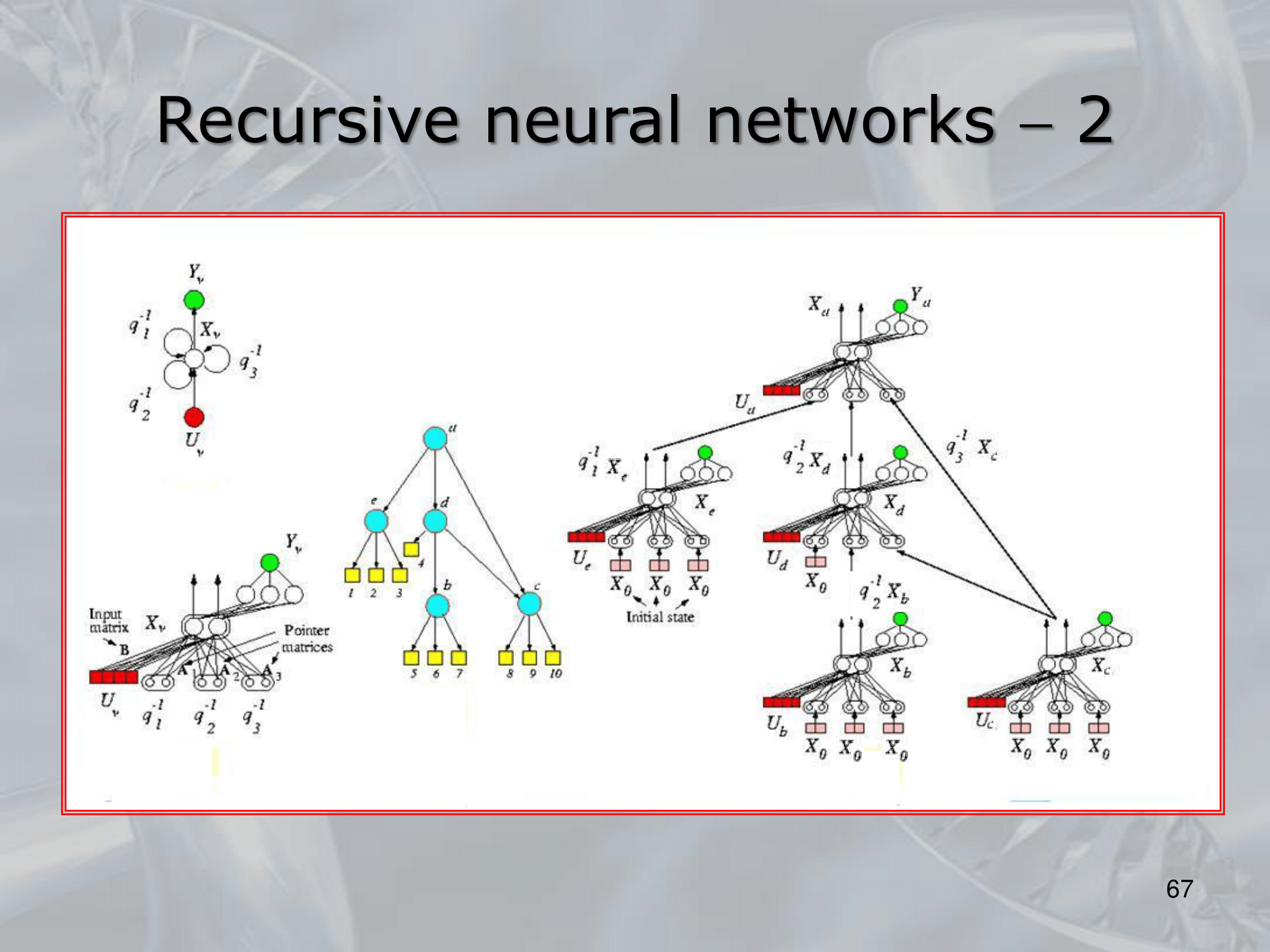
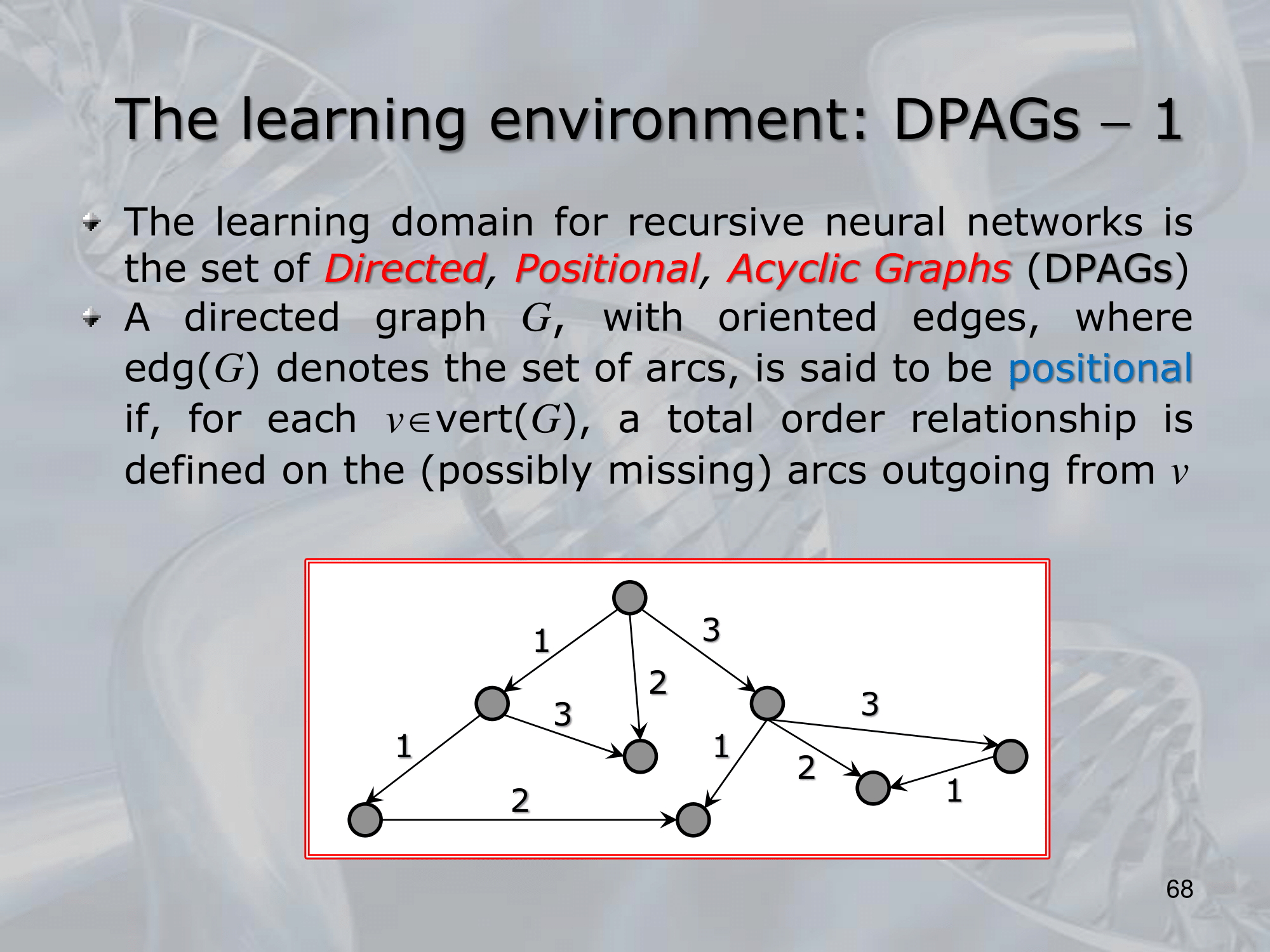
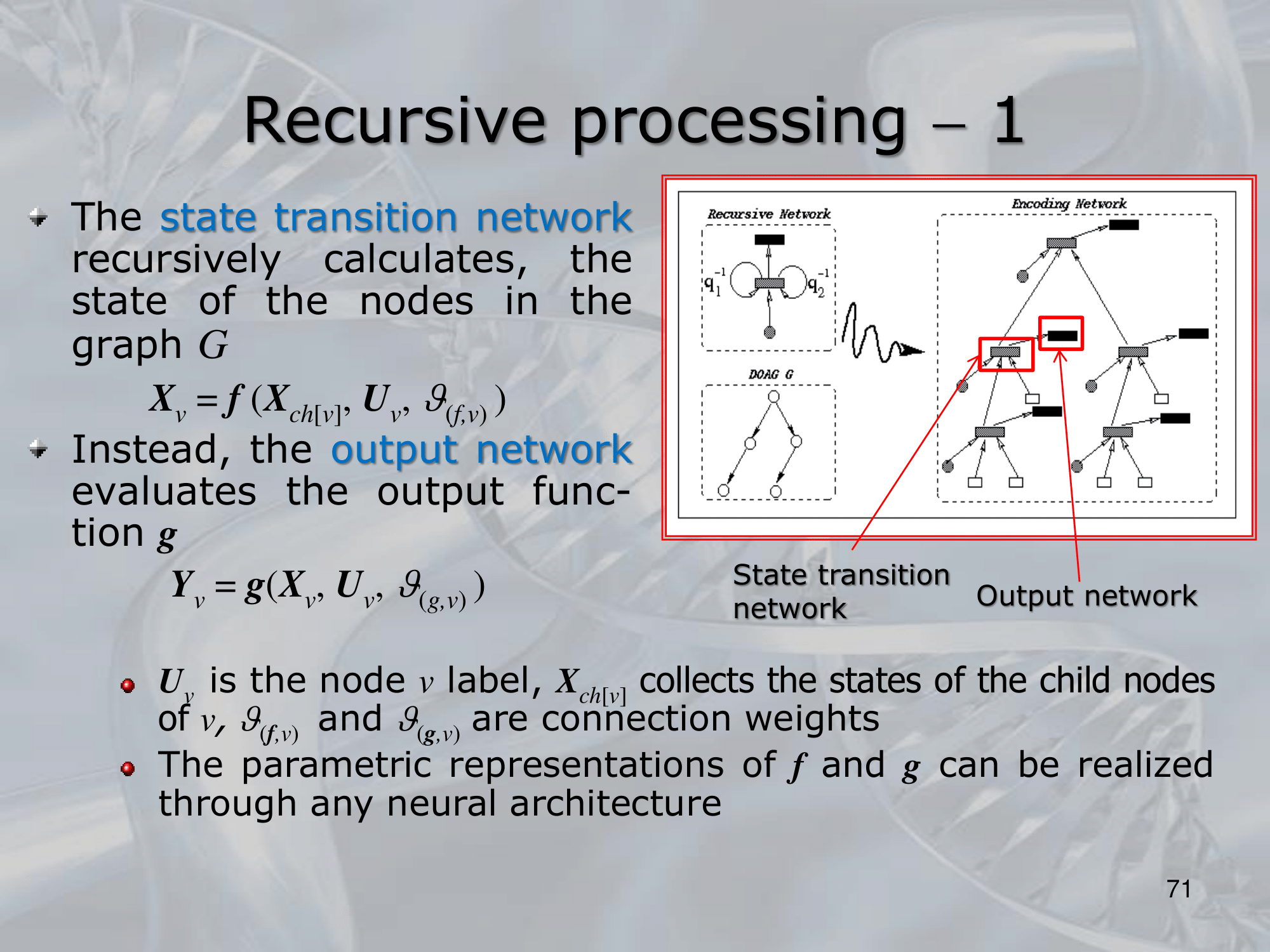
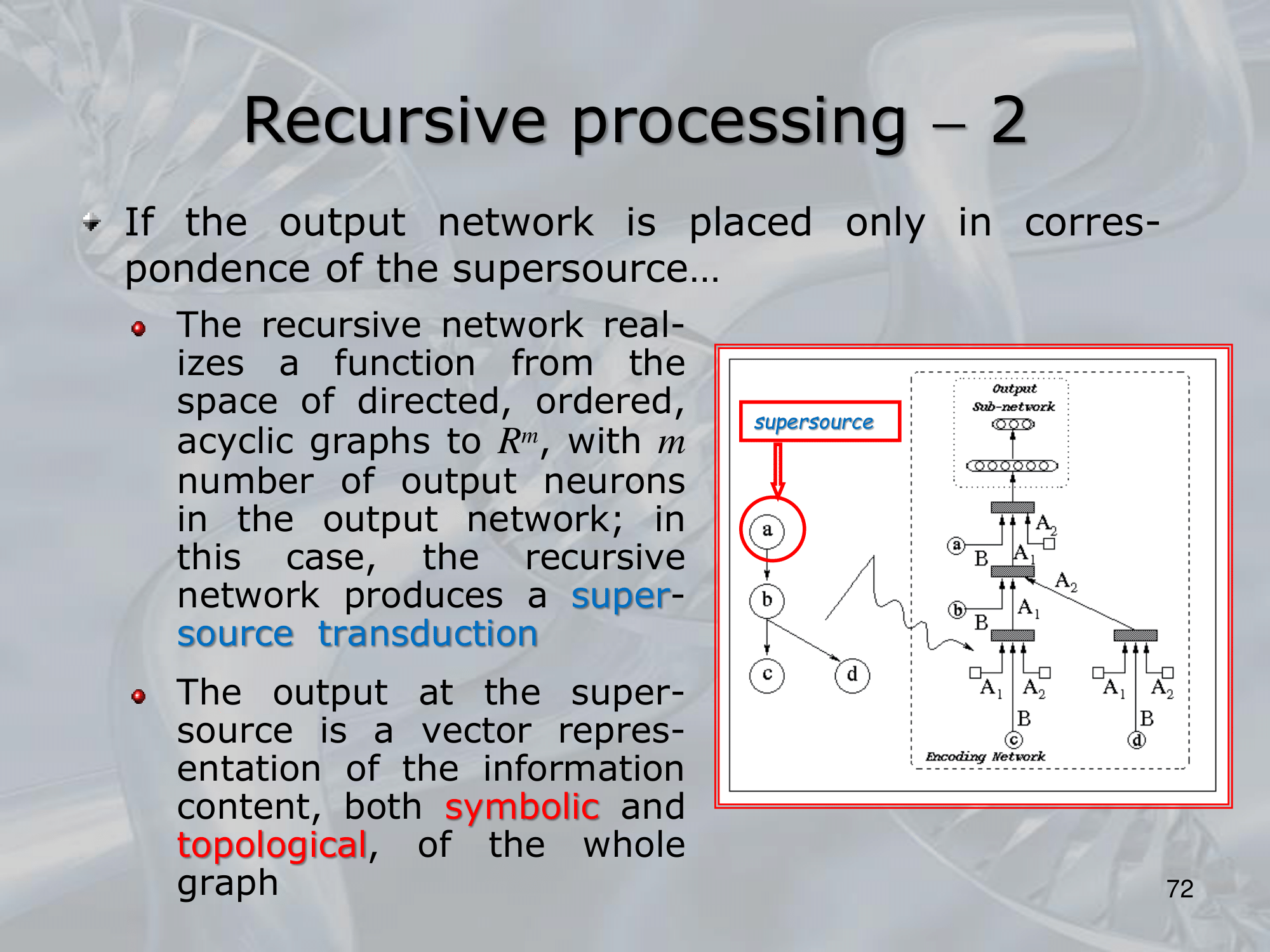
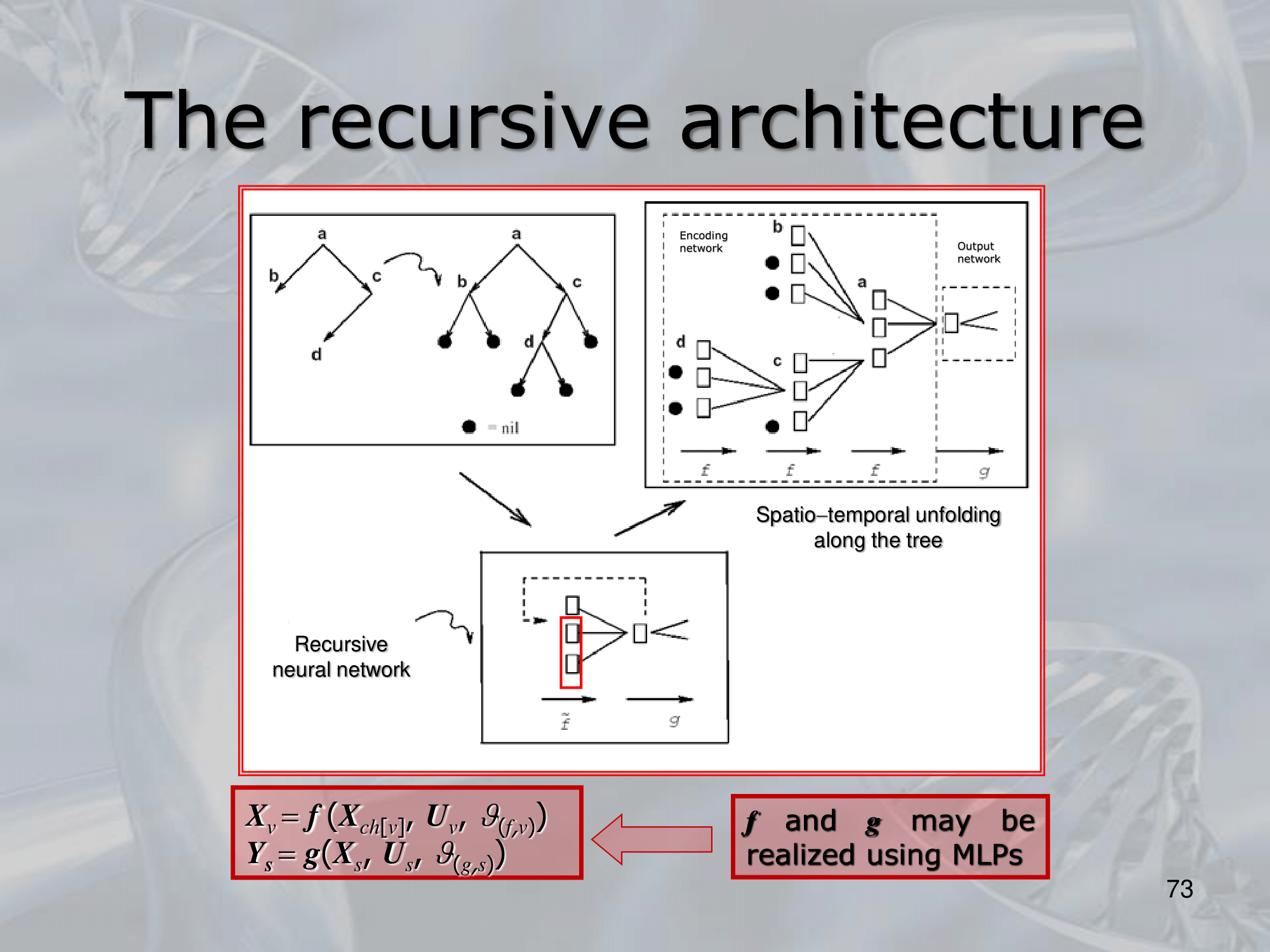
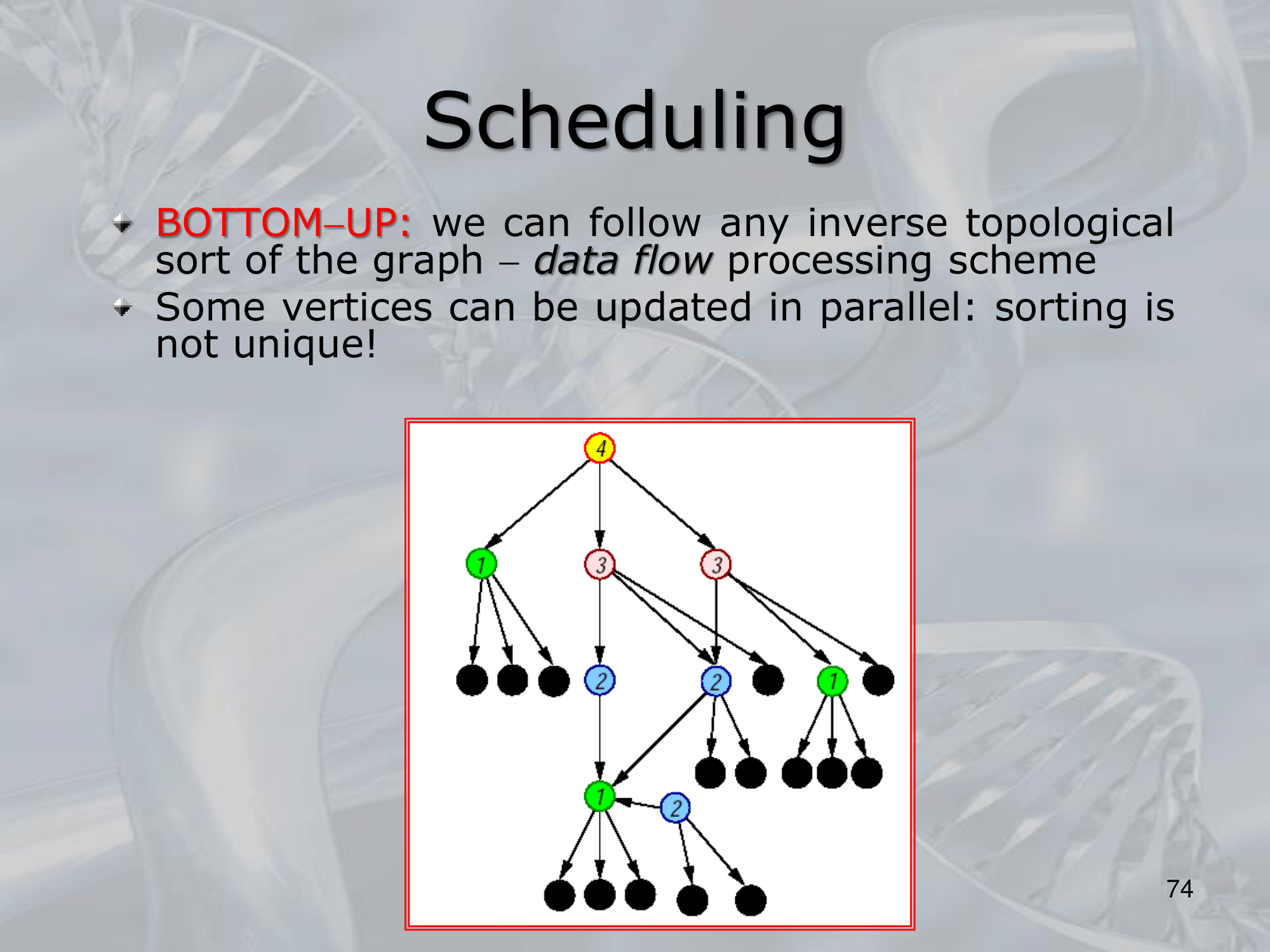
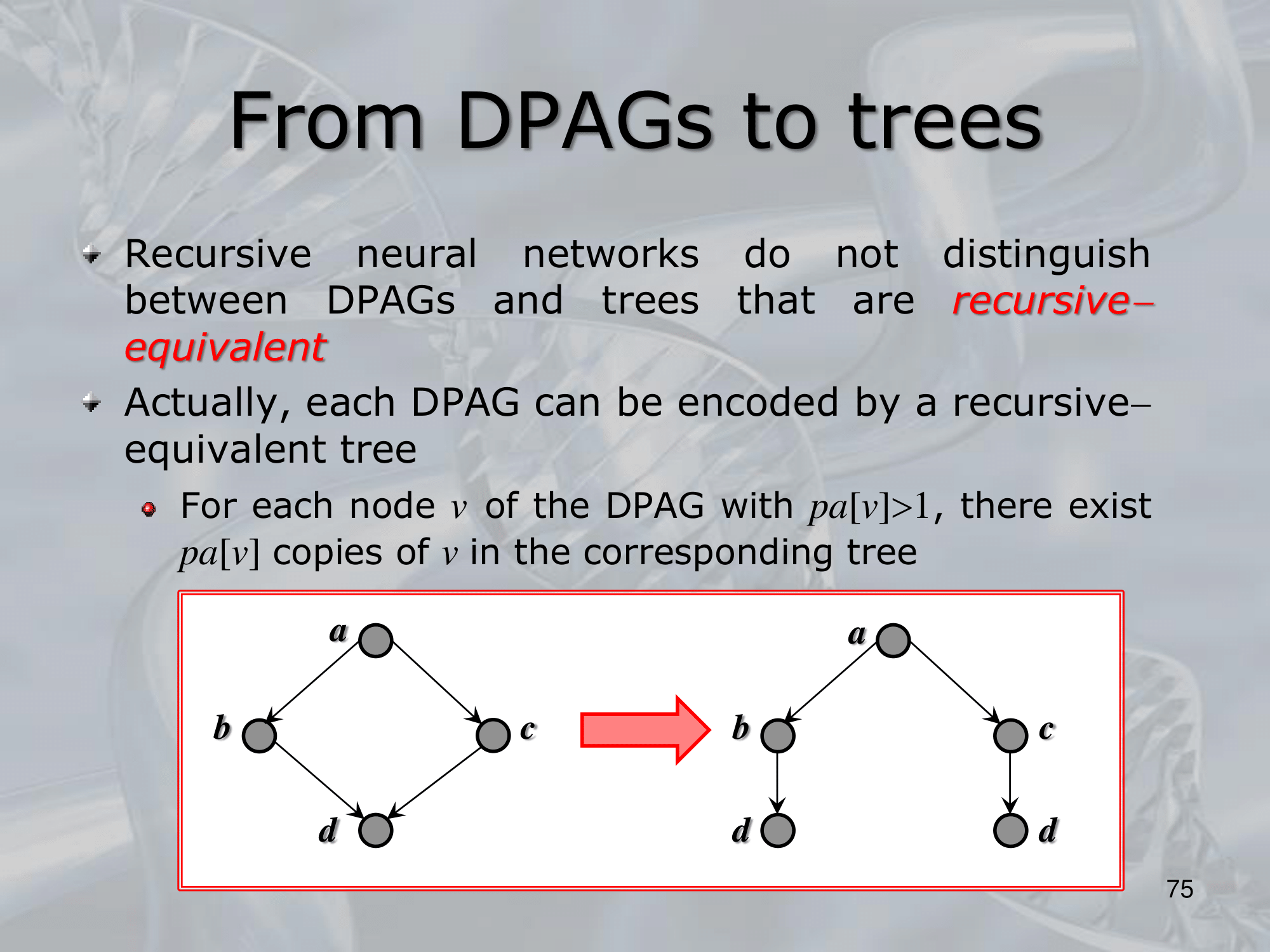
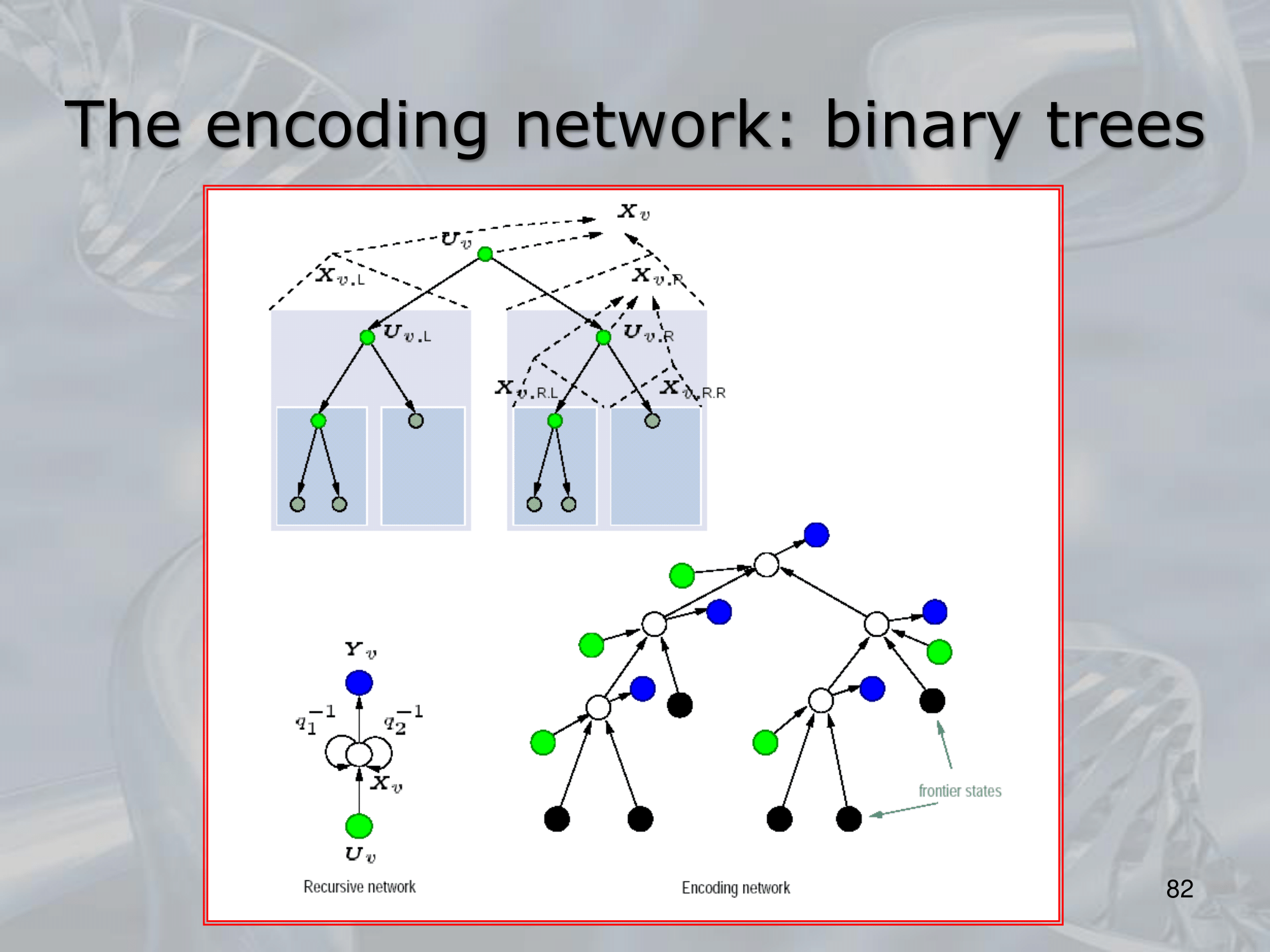
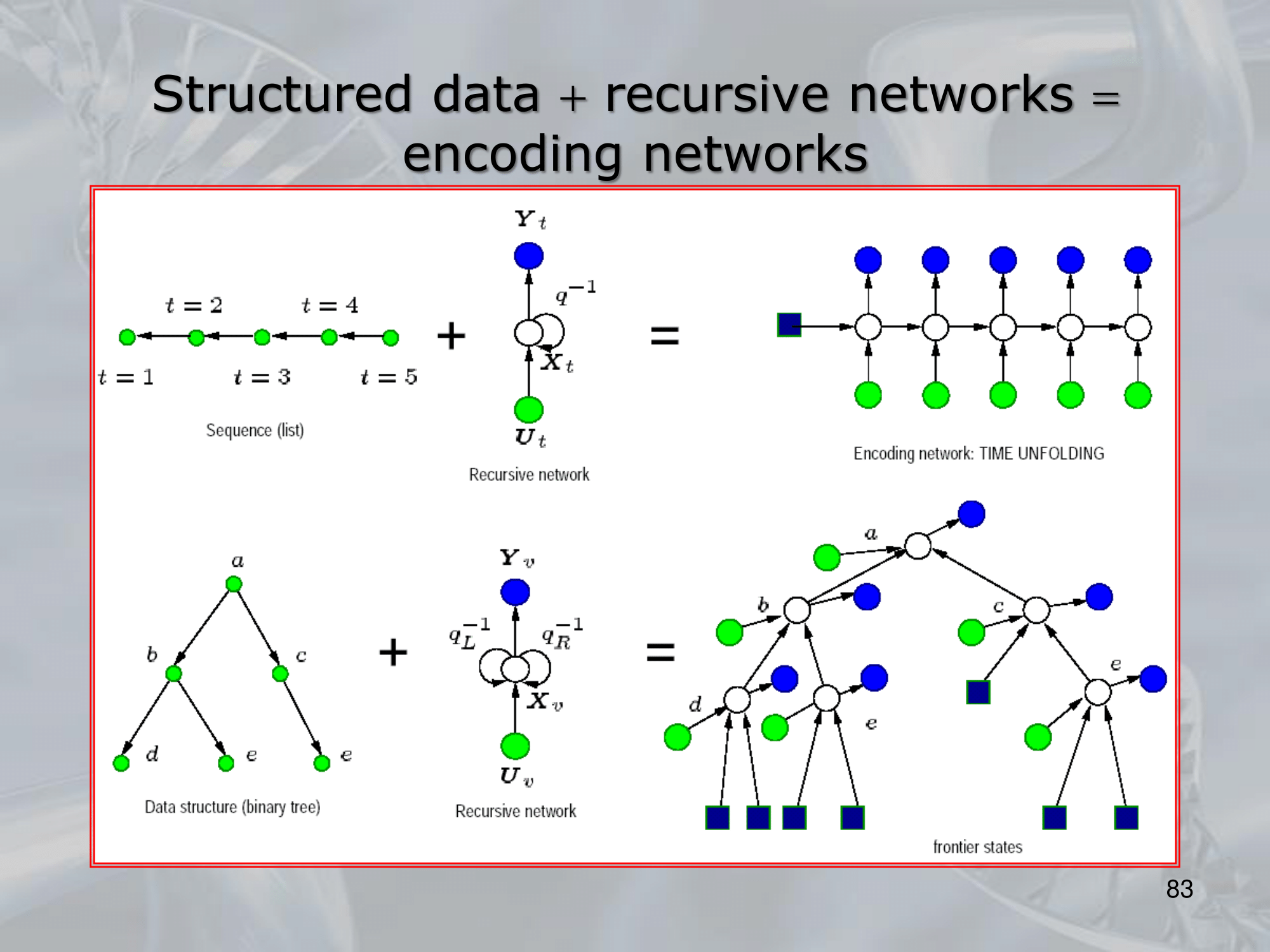
==Recursive Neural Networks (RNNs) are a type of neural network architecture that is designed to process structured input data, such as trees or graphs, where the input can be recursively decomposed into smaller substructures==.
The key idea behind RNNs is to define a neural network architecture that can be applied recursively to the substructures of the input, allowing the network to build up a representation of the entire input by combining information from its substructures. This is typically done by defining a set of local transition functions that operate on each substructure, and using these functions to propagate information up the tree or graph structure.
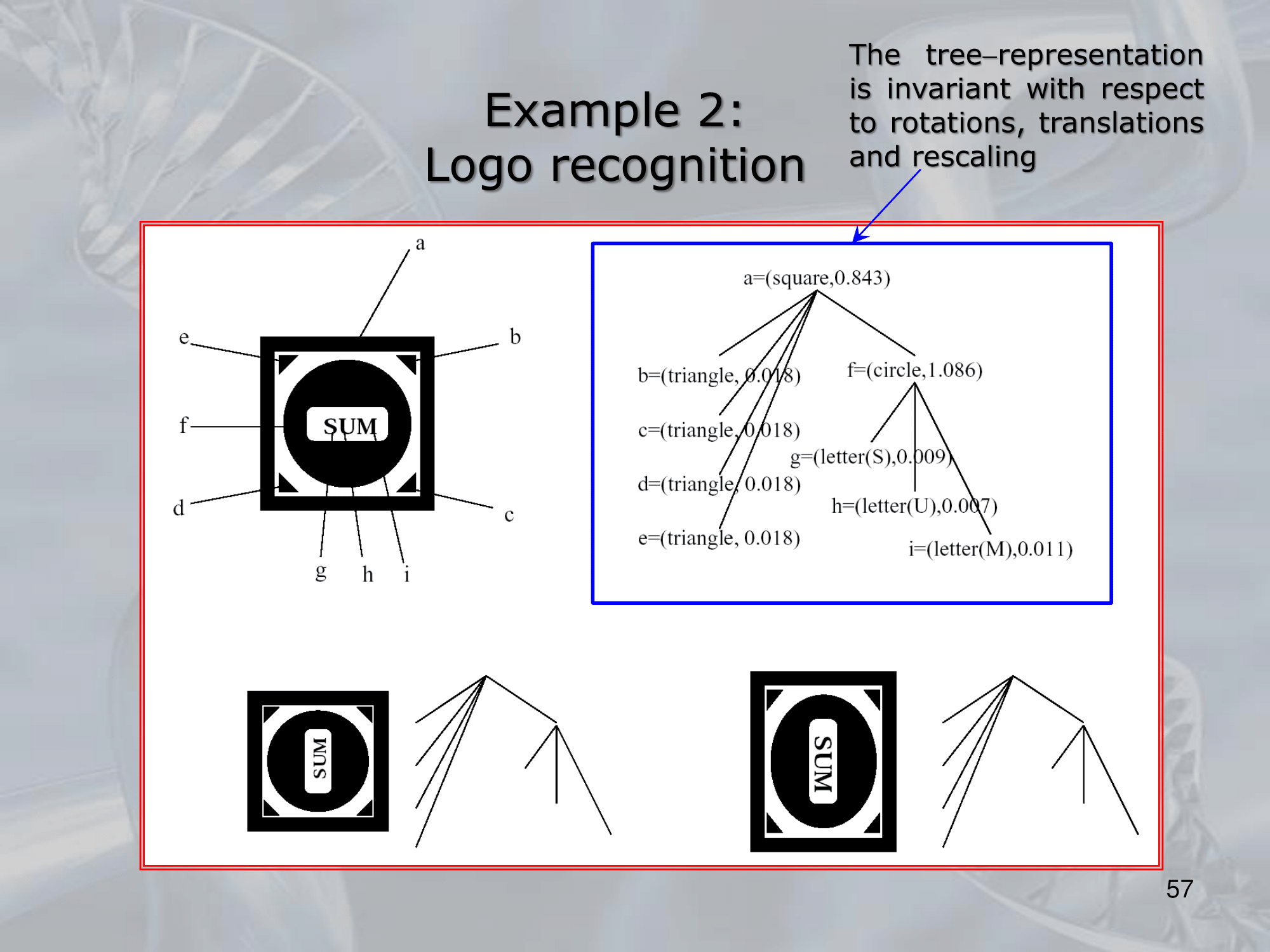
There are several variations of RNNs, including Recursive Autoencoders, Recursive Neural Tensor Networks, and Tree-LSTMs, each with their own specific architectural features and use cases.
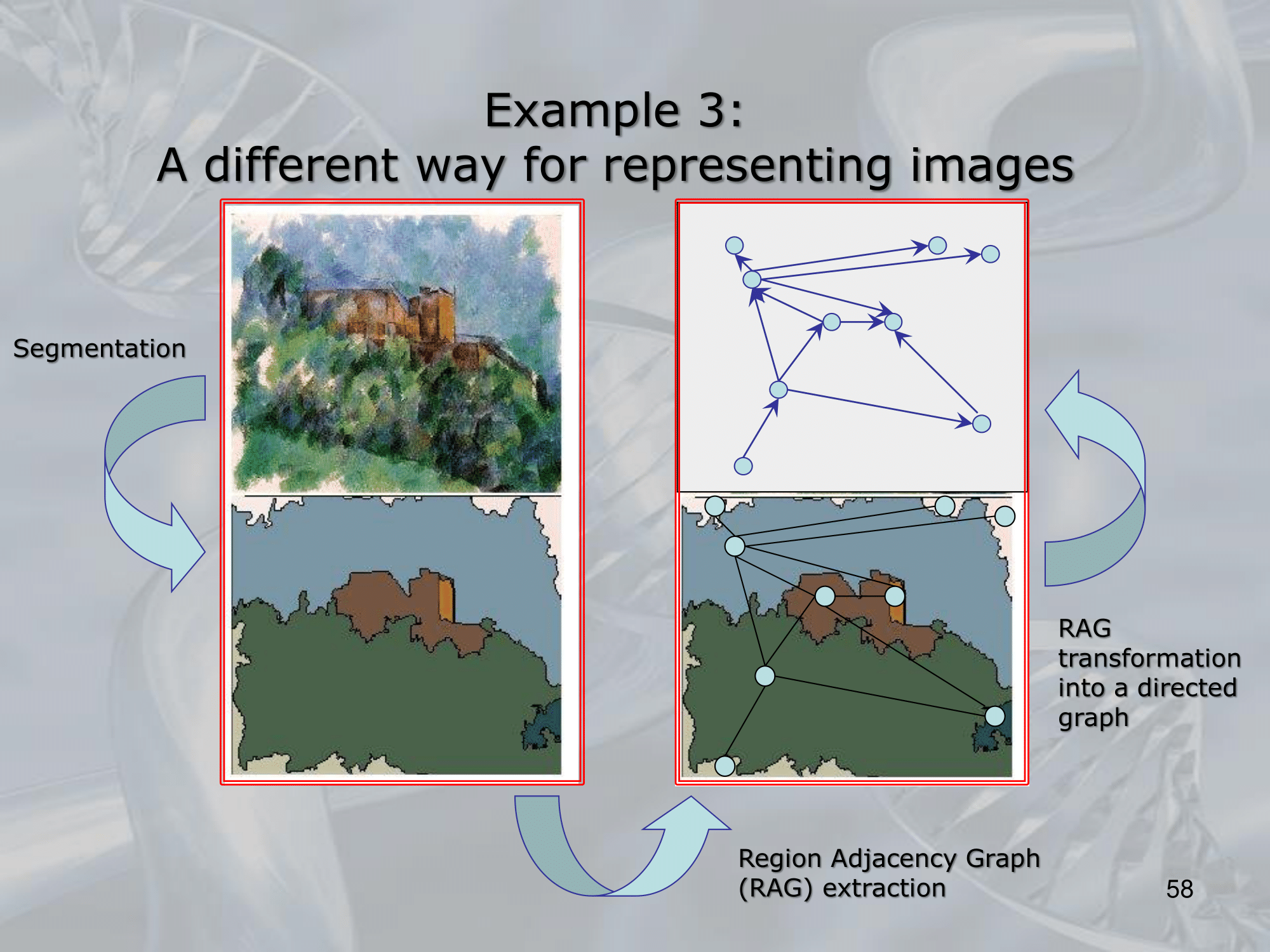
RNNs have been used successfully in a variety of applications, including natural language processing, computer vision, and robotics. They are particularly useful for tasks that involve structured data, such as parsing or semantic analysis, where the structure of the input is critical to understanding its meaning.
One limitation of RNNs is that they can be computationally expensive and difficult to train, particularly for large-scale problems. However, recent advances in deep learning have led to the development of more efficient and scalable RNN architectures, making them an increasingly important tool for processing structured data in machine learning.
What is the V-C Dimension?
The Vapnik-Chervonenkis (VC) dimension is a measure of the complexity or capacity of a machine learning model, which characterizes its ability to fit arbitrary training data. It was introduced by Vladimir Vapnik and Alexey Chervonenkis in the 1970s as a mathematical framework for analyzing the generalization performance of classifiers.
In essence, the VC dimension is the maximum number of points that a model can shatter or separate in all possible ways, i.e., it can classify any dichotomy of the points without making any mistakes. More formally, the VC dimension of a binary classification model is defined as the size of the largest set of points that can be shattered by the model, where shattering means that the model can classify any possible labeling of the points as positive or negative examples.
The VC dimension is a fundamental concept in the theory of machine learning, as it provides a way to quantify the trade-off between model complexity and generalization performance. Models with high VC dimension have more capacity to fit complex patterns in the data, but they also have a higher risk of overfitting and performing poorly on unseen data. On the other hand, models with low VC dimension have less capacity but may generalize better.
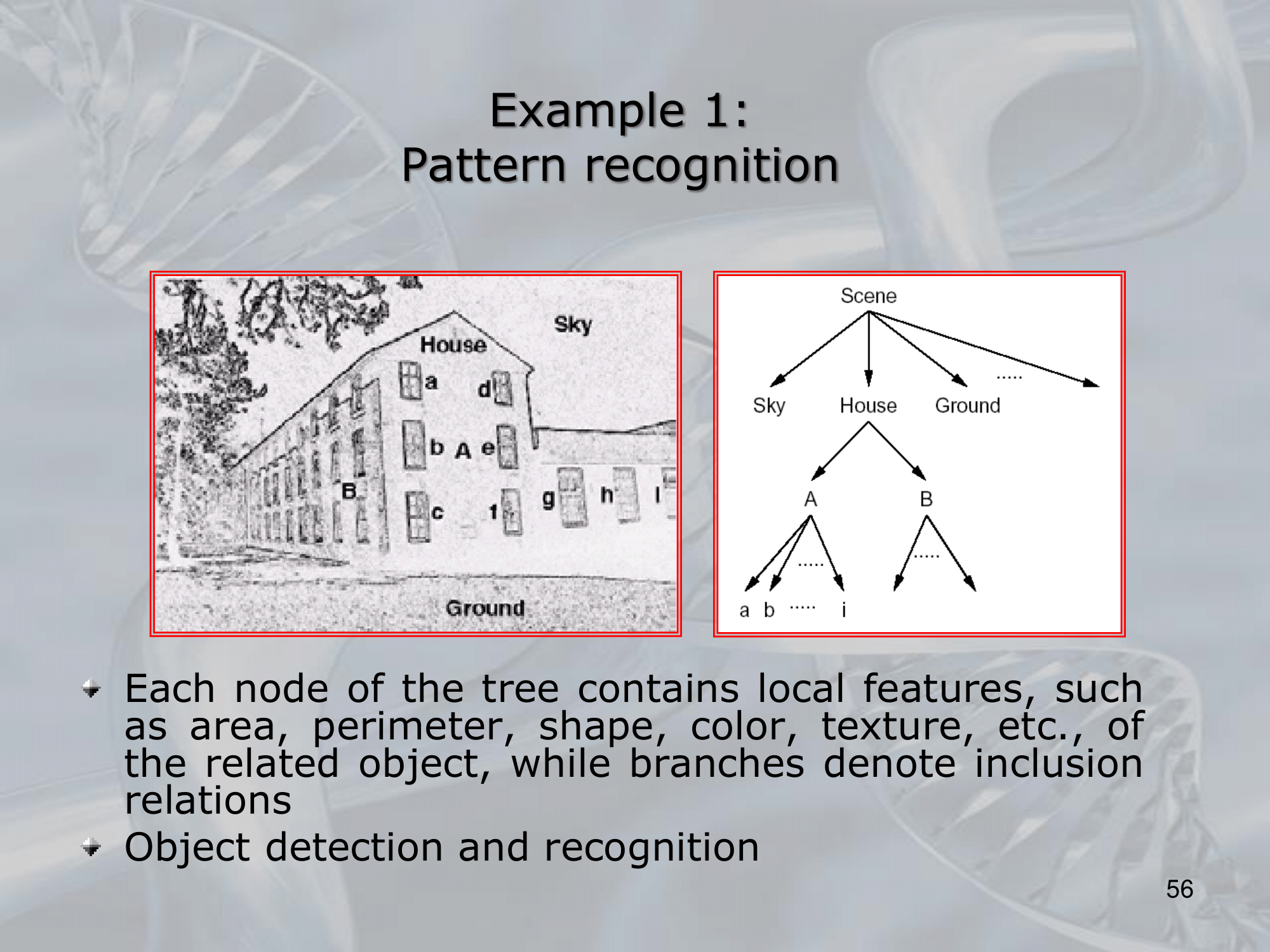
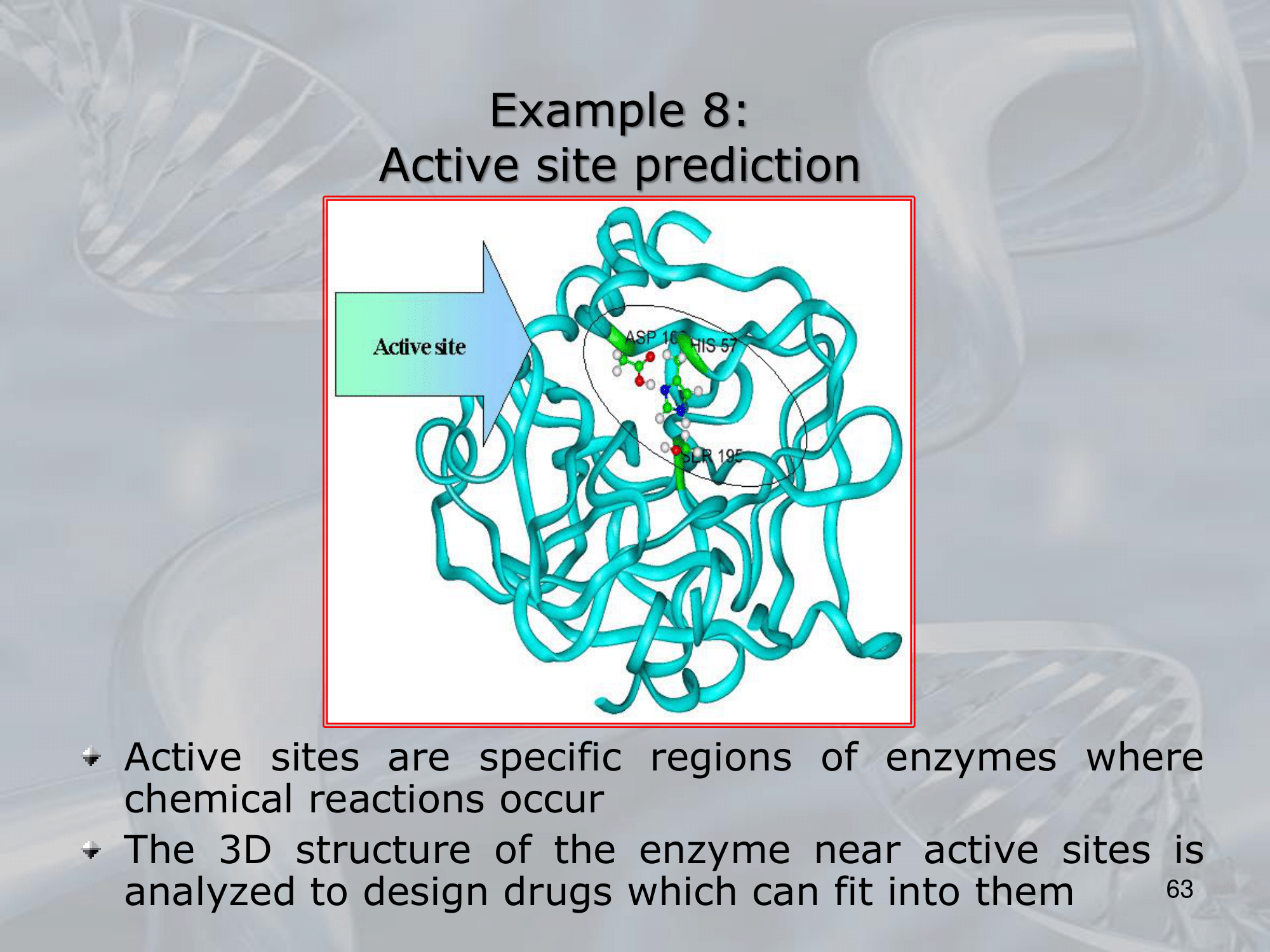
The purpose of these nets was to analyze data that had a hierarchical structure.
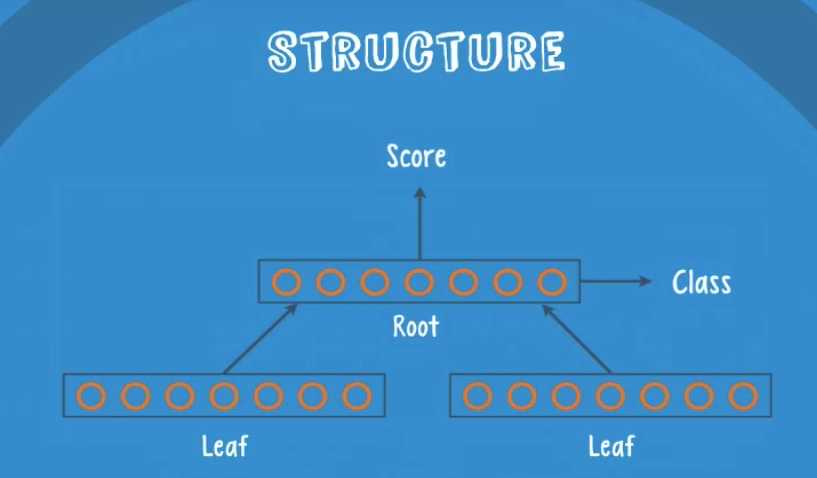
An RNTN has 3 basic components: a parent group which we’ll call the root, and a child group which we’ll call the leaves (each RNTN has at least and usually 2 leaves).
Each group is simply a collection of neurons, where the number of neurons depends on the complexity of the input data.
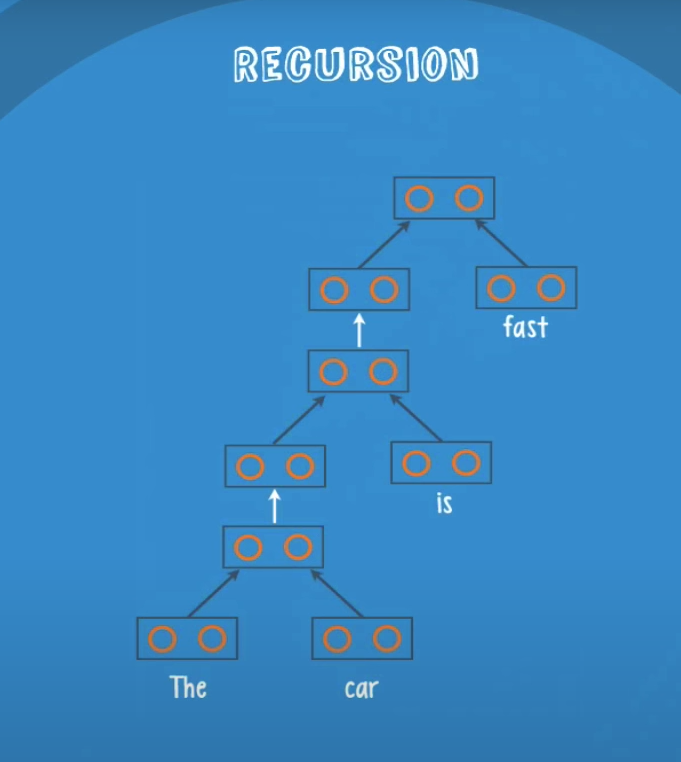
The principal characteristic of an RNTN is the recursion, let’s see an example:
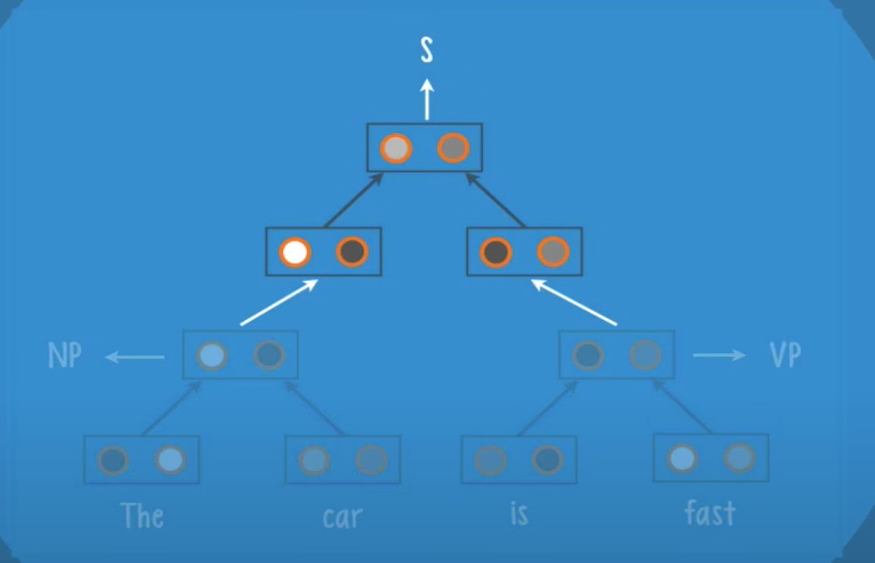
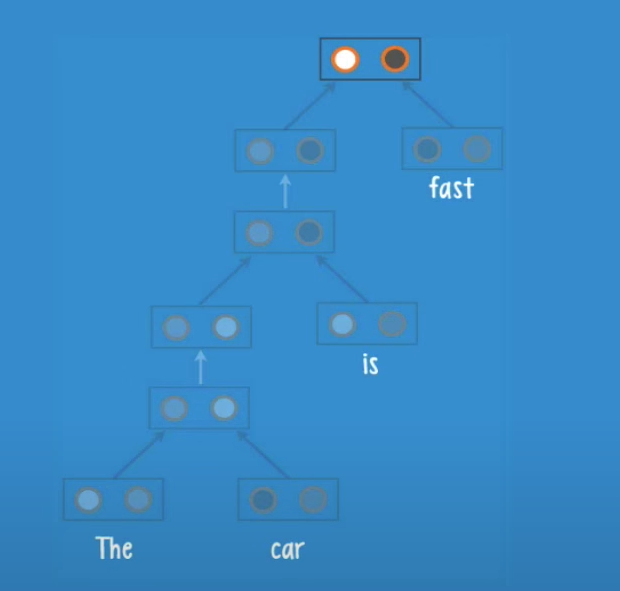
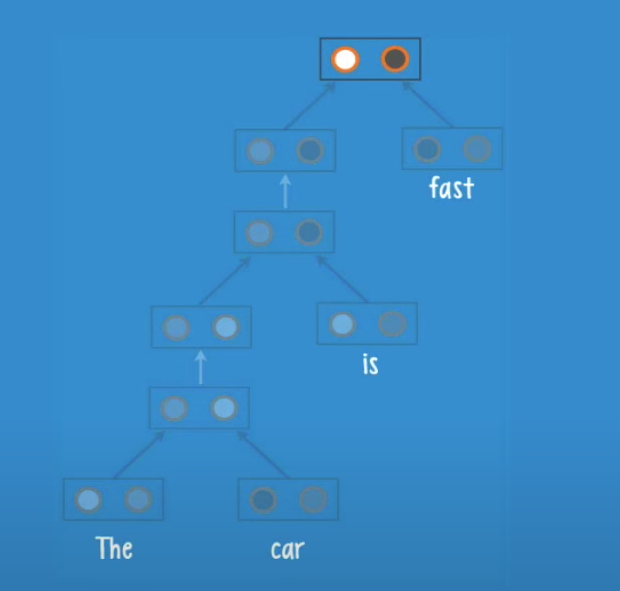
We will now feed an english sentence ‘The car is fast’ to an RNTN with the structure seen before.
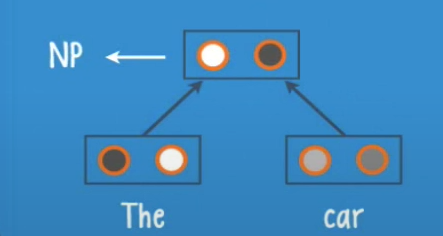
Let’s see how the recursion works, note that we do not actually pass words to the network but a vector of numbers that represents them.
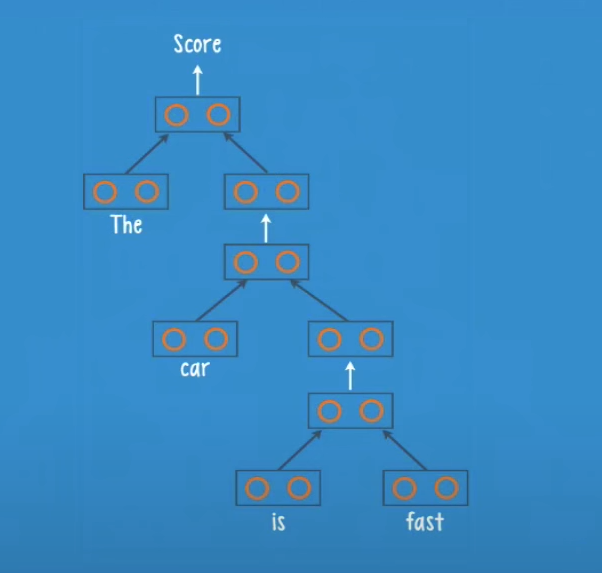
In this case we have the leaves ‘The’ and ‘car’ they get pass to the root, and the neurons inside the root will give us a class and a score
The score represents the quality of the current parse.
The class represents the encoding of a structure in the current parse (for example )
From this point, the net starts the recursion.
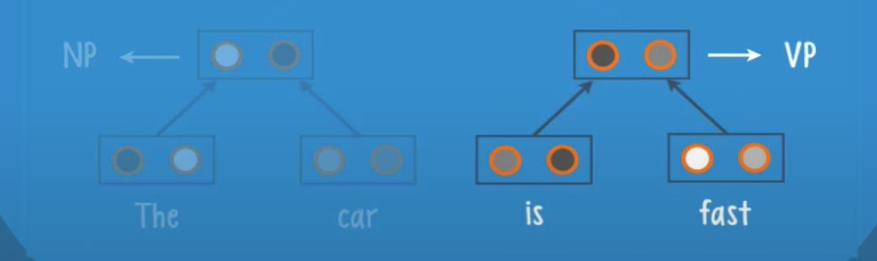
The net receives the current parse and adds a new leaf ‘is’, and create a new parse like before, and so on until we finish all the words in the sentence.
The result is a final class and a final score.
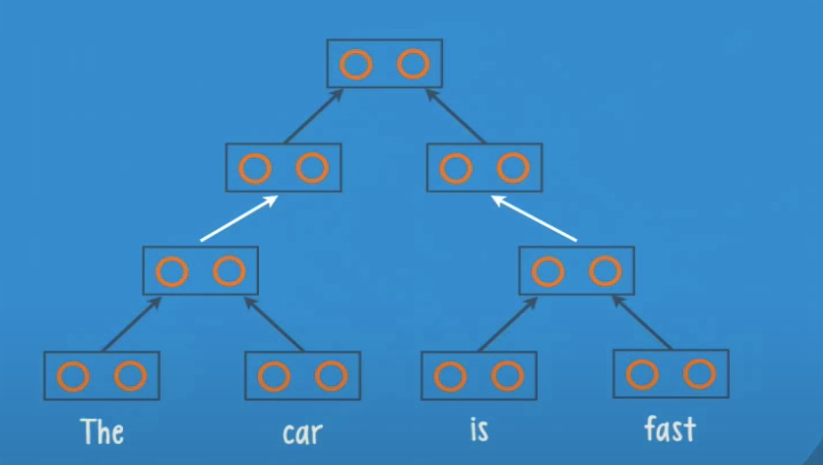
The networks also has to choose a structure, listed below are the three different possible structure for our network, our RNTN decides every best substructure based on the score value produced by each root group, at each step of the recursive process, this way the net will produce as the final output the highest score.
Once the net has the final structure, it backtracks to figure out the right grammatical label for each part of the sentence.
For example, here founds that the first label is a noun phrase (NP)
Then found the second label a verb phrase (VP)
Lastly it labels the final root as the source (S)
RNTN are trained using backpropagation, using a set of trained labeled structures, and a cost function that will give a higher score based on how similar the target structure and the output structure are.
 Let’s see how the recursion works, note that we do not actually pass words to the network but a vector of numbers that represents them.
Let’s see how the recursion works, note that we do not actually pass words to the network but a vector of numbers that represents them.
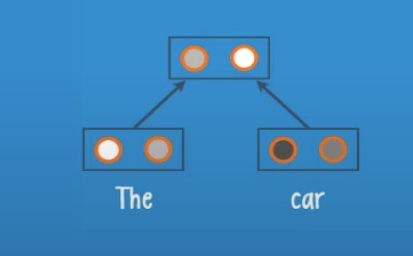 In this case we have the leaves ‘The’ and ‘car’ they get pass to the root, and the neurons inside the root will give us a class and a score
In this case we have the leaves ‘The’ and ‘car’ they get pass to the root, and the neurons inside the root will give us a class and a score
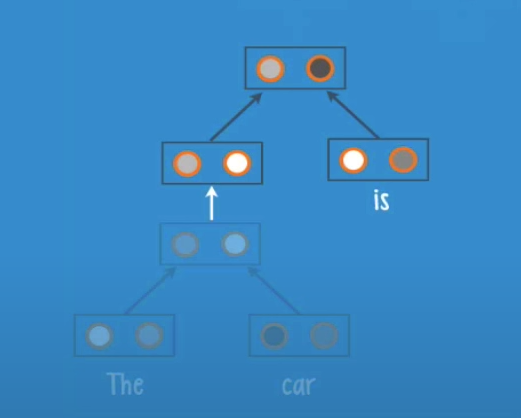 The net receives the current parse and adds a new leaf ‘is’, and create a new parse like before, and so on until we finish all the words in the sentence.
The net receives the current parse and adds a new leaf ‘is’, and create a new parse like before, and so on until we finish all the words in the sentence.
 Then found the second label a verb phrase (VP)
Then found the second label a verb phrase (VP)
 Lastly it labels the final root as the source (S)
Lastly it labels the final root as the source (S)