Questions
- What is Transfer Learning?
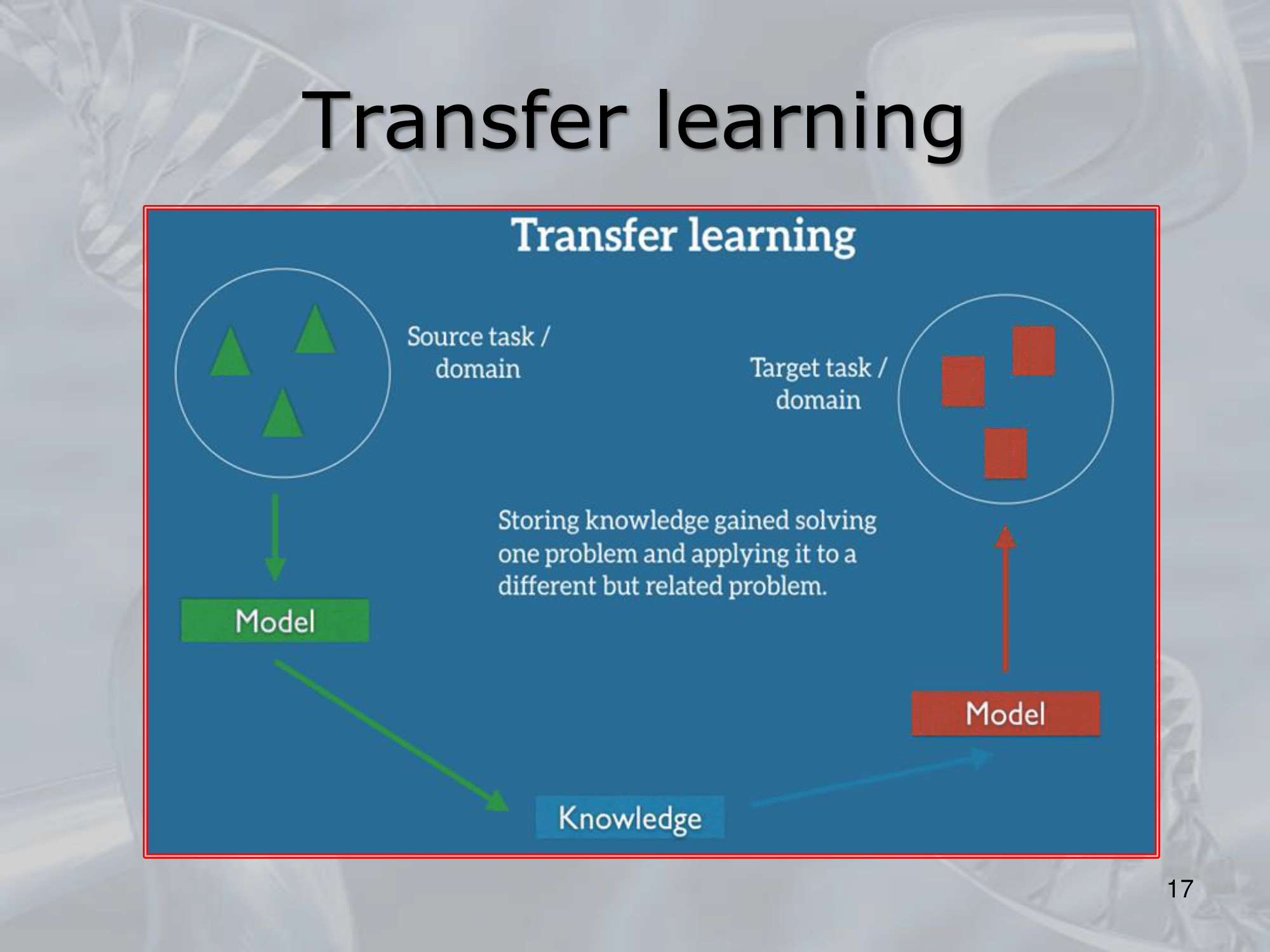
- ==Transfer learning is a machine learning technique where a pre-trained model on a large dataset is adapted to a new task with a smaller dataset.
Instead of training a model from scratch on a new dataset, transfer learning allows you to leverage the knowledge and features learned by a pre-trained model on a similar task or dataset==. - In transfer learning, the pre-trained model is usually a neural network that has been trained on a large dataset, such as ImageNet for image classification tasks.
The model is then adapted to a new task by removing the last layer(s) and adding a new output layer that is specific to the new task.
==The weights of the pre-trained layers are frozen, so that they are not updated during training, and only the weights of the new output layer are learned using the new dataset==. - Transfer learning can help improve the performance of a model on a new task by providing a good starting point for learning relevant features.
This is especially useful in cases where the new dataset is small and it would be difficult to train a model from scratch due to the risk of overfitting.
Transfer learning also reduces the computational cost of training a new model, since the pre-trained model can be used to extract features from the new dataset, rather than re-training the entire model from scratch. - Transfer learning can be applied to a variety of machine learning tasks, including image classification, object detection, natural language processing, and speech recognition.
- ==Transfer learning is a machine learning technique where a pre-trained model on a large dataset is adapted to a new task with a smaller dataset.
- What is Data Augmentation?
- Data augmentation is a technique used to increase the amount of training data by applying various transformations to the original dataset.
This technique is commonly used in machine learning and deep learning to improve model performance by reducing overfitting and increasing model generalization. - Data augmentation techniques can vary depending on the type of data being used, but some common examples include:
- Image augmentation: This involves applying transformations to images, such as flipping, rotating, scaling, cropping, changing brightness or contrast, or adding noise or blur.
- Text augmentation: This involves applying transformations to text data, such as replacing words with synonyms, changing the word order, or adding grammatical variations.
- Audio augmentation: This involves applying transformations to audio data, such as changing the pitch, speed, or volume.
- By applying these transformations, the augmented dataset can capture more diverse examples and variations, allowing the model to generalize better to new and unseen data.
- ==Data augmentation can also help to address class imbalance, which is a common problem in machine learning where some classes have much fewer examples than others==.
By applying data augmentation techniques to the smaller classes, we can balance the number of examples for each class and improve model performance. - Overall, data augmentation is a powerful technique for improving the robustness and performance of machine learning models, and it is often used in combination with other techniques such as transfer learning and regularization.
- Data augmentation is a technique used to increase the amount of training data by applying various transformations to the original dataset.
- What is Synthetic Data?
- Synthetic data refers to artificially generated data that mimics the characteristics and patterns of real-world data.
This data can be generated using various techniques, such as computer simulations, generative models, or rule-based algorithms. - The use of synthetic data is becoming increasingly popular in machine learning and deep learning because it can overcome the limitations of real-world data, such as data scarcity, privacy concerns, or data quality issues.
Synthetic data can be used to augment or replace real-world data in training models, and it can also help to create more diverse and representative datasets. - Some of the benefits of using synthetic data include:
- Scalability: Synthetic data can be generated in large quantities and with different levels of complexity, allowing us to create datasets that are more diverse and representative of the real world.
- Privacy: Synthetic data can be generated without revealing sensitive or identifiable information, making it useful for applications where data privacy is a concern.
- Cost-effectiveness: Synthetic data can be generated at a lower cost than collecting and annotating real-world data, making it a cost-effective solution for training machine learning models.
- Flexibility: Synthetic data can be generated with specific characteristics or patterns, allowing us to test and validate models under different scenarios or conditions.
- Some of the challenges associated with using synthetic data include ensuring that the generated data is representative of the real-world data and that it captures the relevant patterns and characteristics needed for training the model.
Additionally, it is important to ensure that the synthetic data is not biased or overfit to a specific use case.
- Synthetic data refers to artificially generated data that mimics the characteristics and patterns of real-world data.
—————————————————————
Slides with Notes

IMPORTANTE How to make up for the lack of data?: Transfer Learning Data Augumentation (alter already existing data, and consider them as new data) Generation of Synthetic Data: (use ML approach, like GANs Generative Adversarila Networks, to create new data, on the basis of what data we have)