What is there to say about Convolutional Neural Networks?
Convolutional Neural Networks (CNNs) are a type of neural network commonly used for image classification, object detection, and other computer vision tasks.
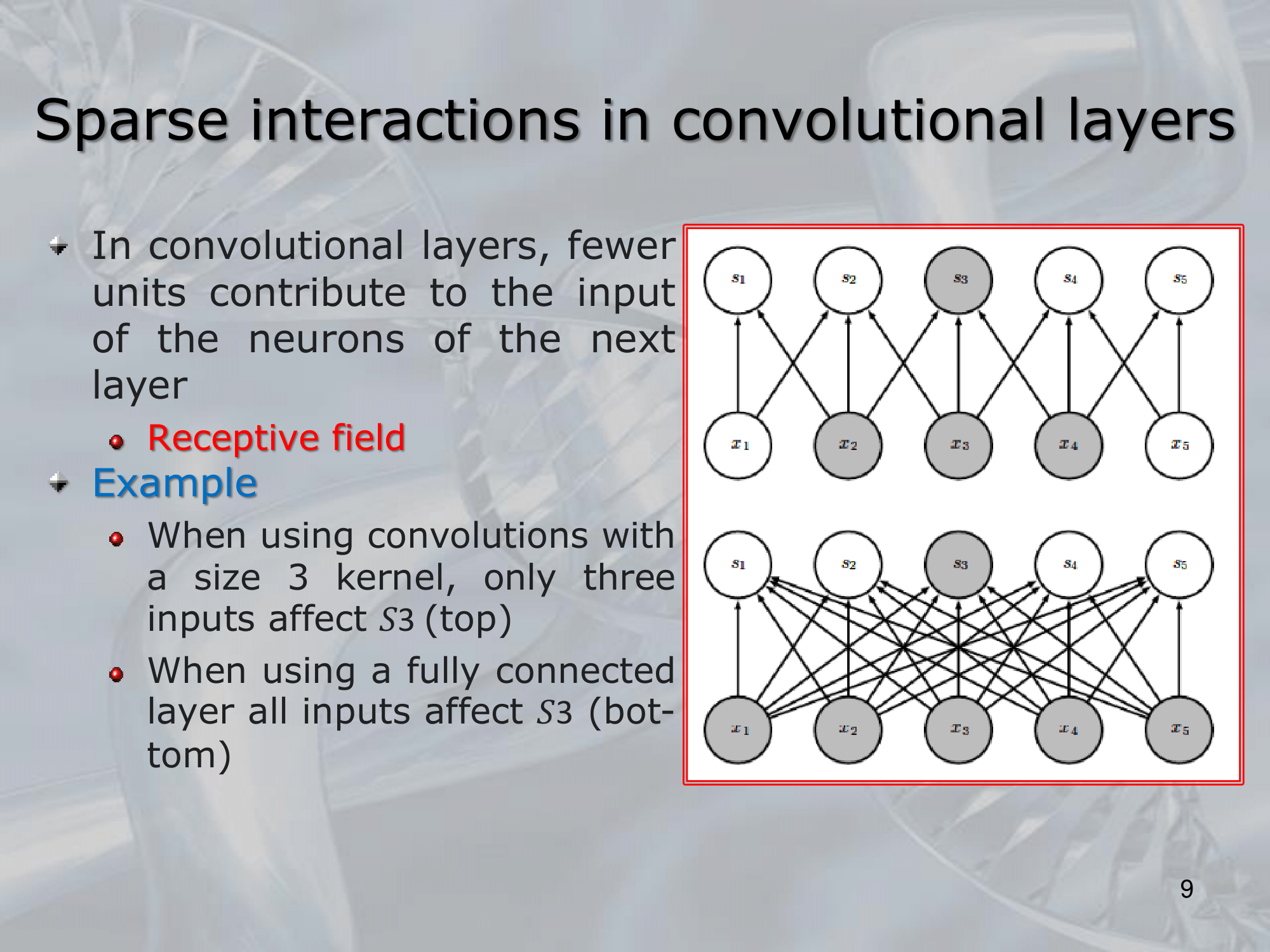
==CNNs consist of multiple layers, each of which performs a specific operation on the input data. The first layer is typically a convolutional layer, which applies a set of filters to the input image, each of which extracts a specific feature from the image==.
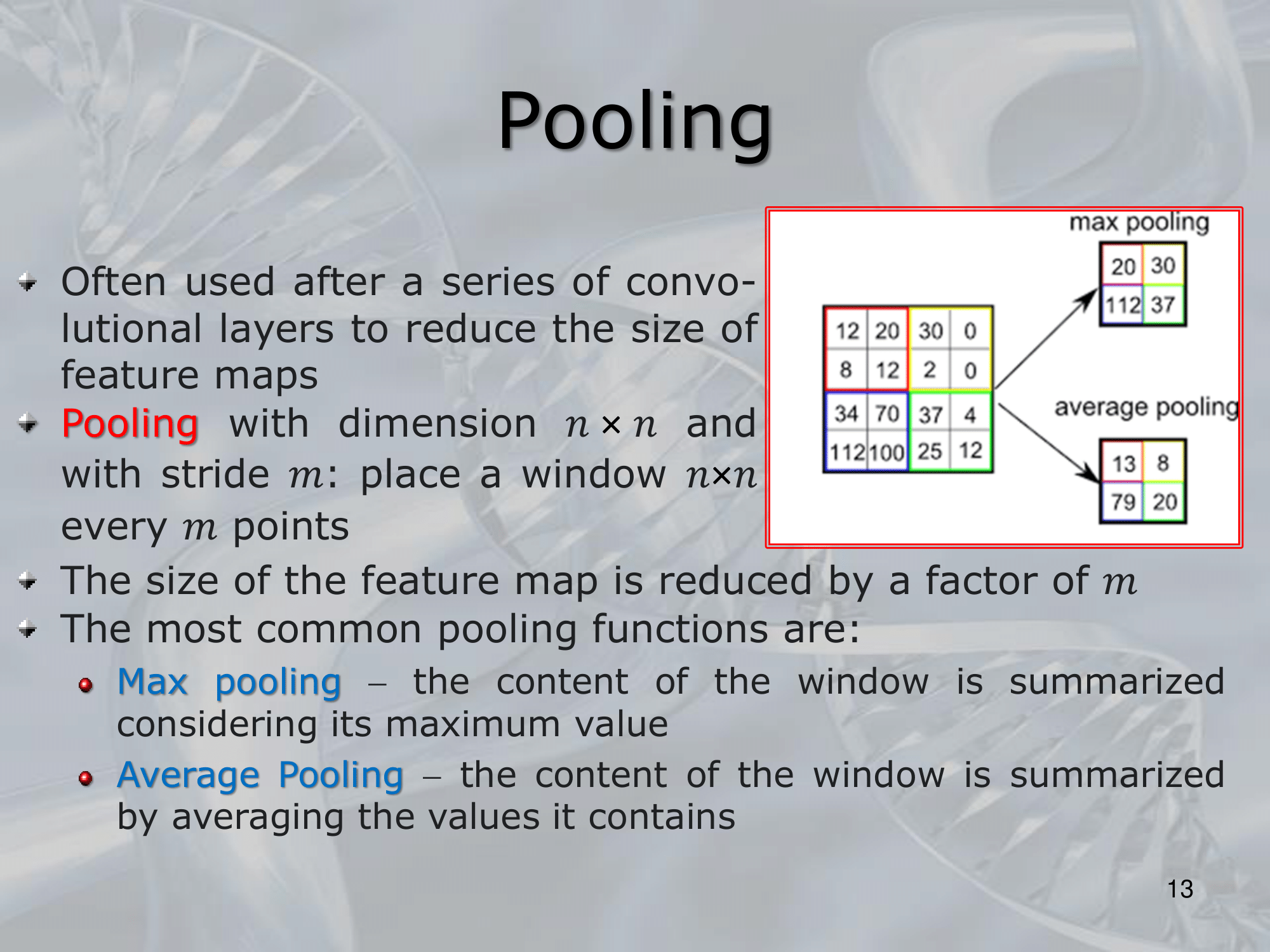
Subsequent layers typically perform operations such as pooling, which reduces the spatial dimensions of the data while preserving important features, and fully connected layers, which perform the final classification or regression task.
One of the key advantages of CNNs is their ability to automatically learn features from raw data, without the need for hand-crafted features. This makes them particularly useful for tasks where the relevant features are not known in advance, such as image recognition.
CNNs have been applied to a wide range of tasks in bioinformatics, including gene expression analysis, protein structure prediction, and drug discovery. They have also been used for image analysis in medical imaging, such as detecting tumors in MRI scans.
However, like any machine learning algorithm, CNNs are not a silver bullet and can have limitations depending on the specific task and data. Careful consideration of model design, hyperparameters, and training procedures is necessary to ensure optimal performance.
How do CNNs work?
Convolutional Neural Networks (CNNs) are a type of neural network commonly used in image recognition and computer vision tasks. CNNs use a series of convolutional layers to extract relevant features from the input image, which are then processed by fully connected layers to make a prediction.
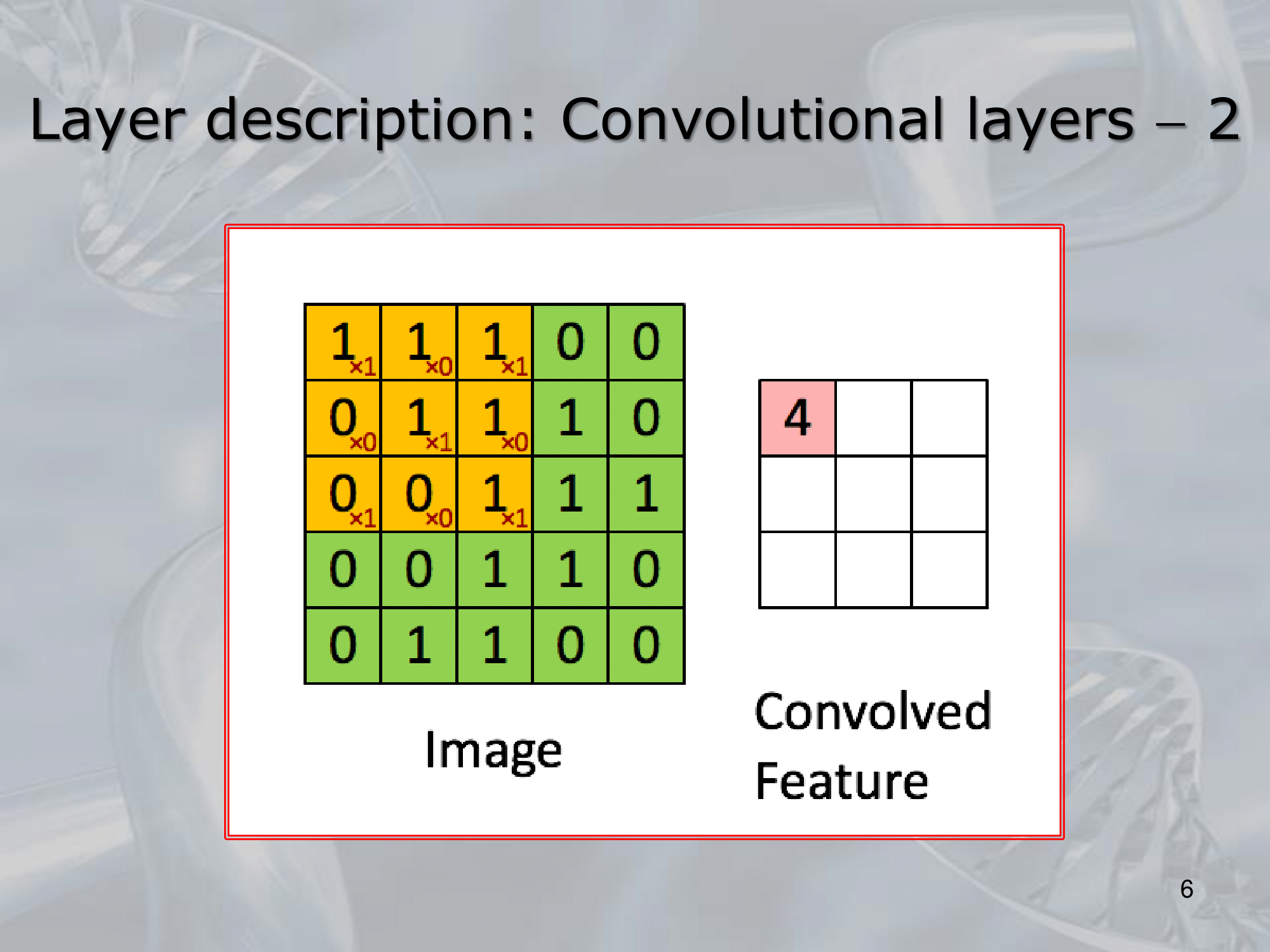
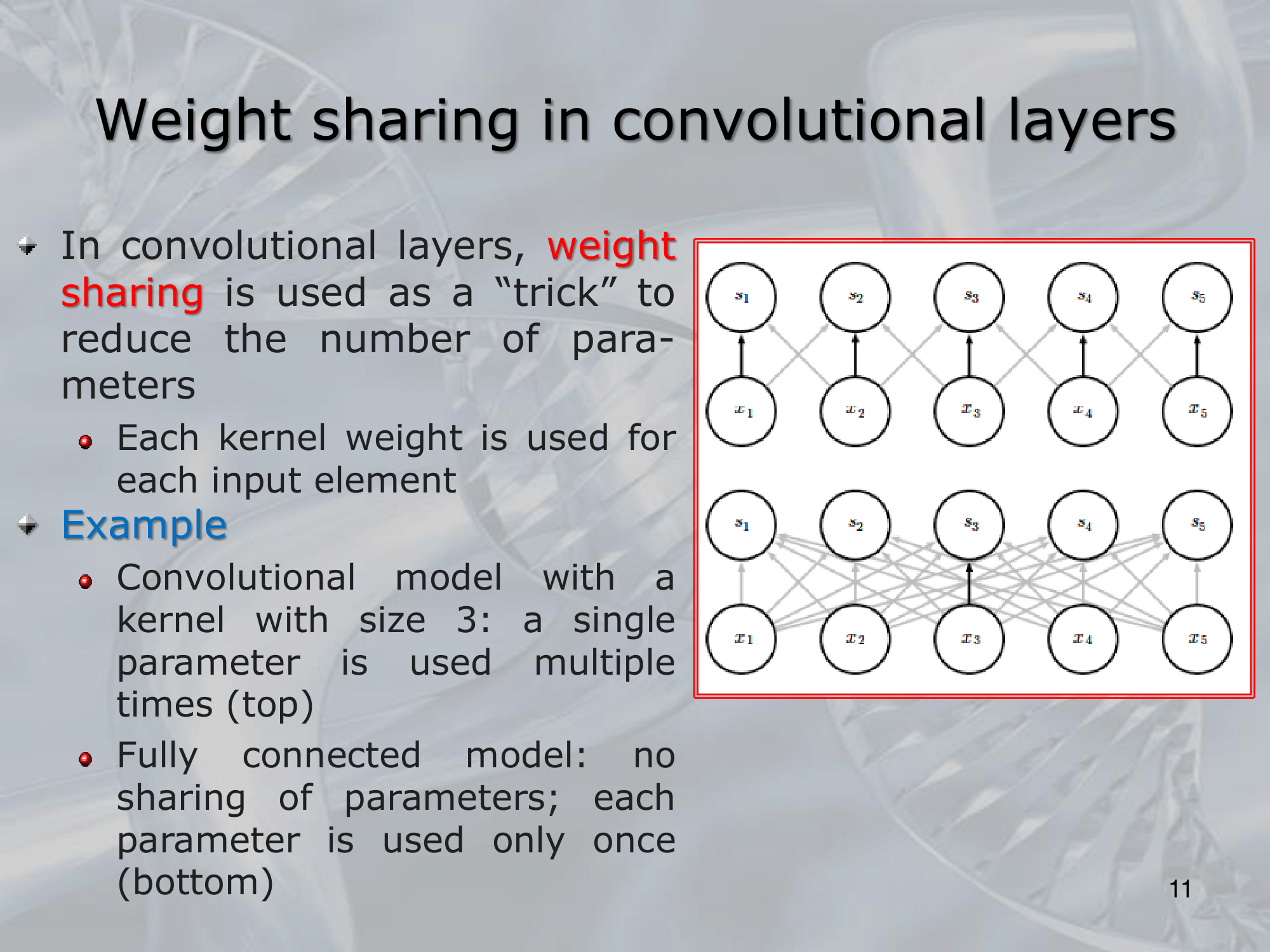
The basic building block of a CNN is the convolutional layer, which performs a convolution operation on the input image using a set of learnable filters. Each filter is a small matrix of weights that is “slid” across the image, computing a dot product at each location to produce a new feature map. The weights of the filters are learned during training, and they represent the features that the network is trying to extract from the input image.
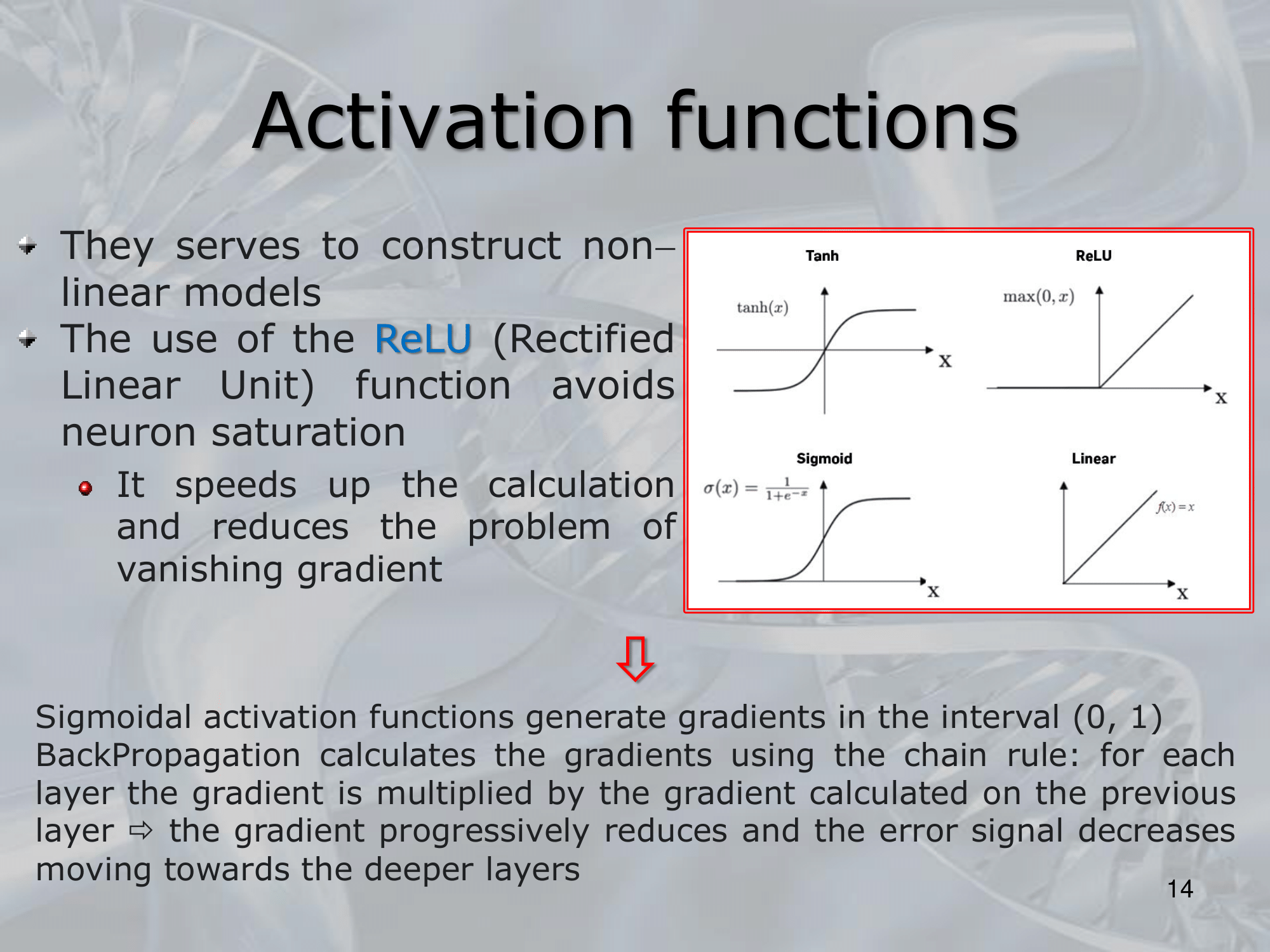
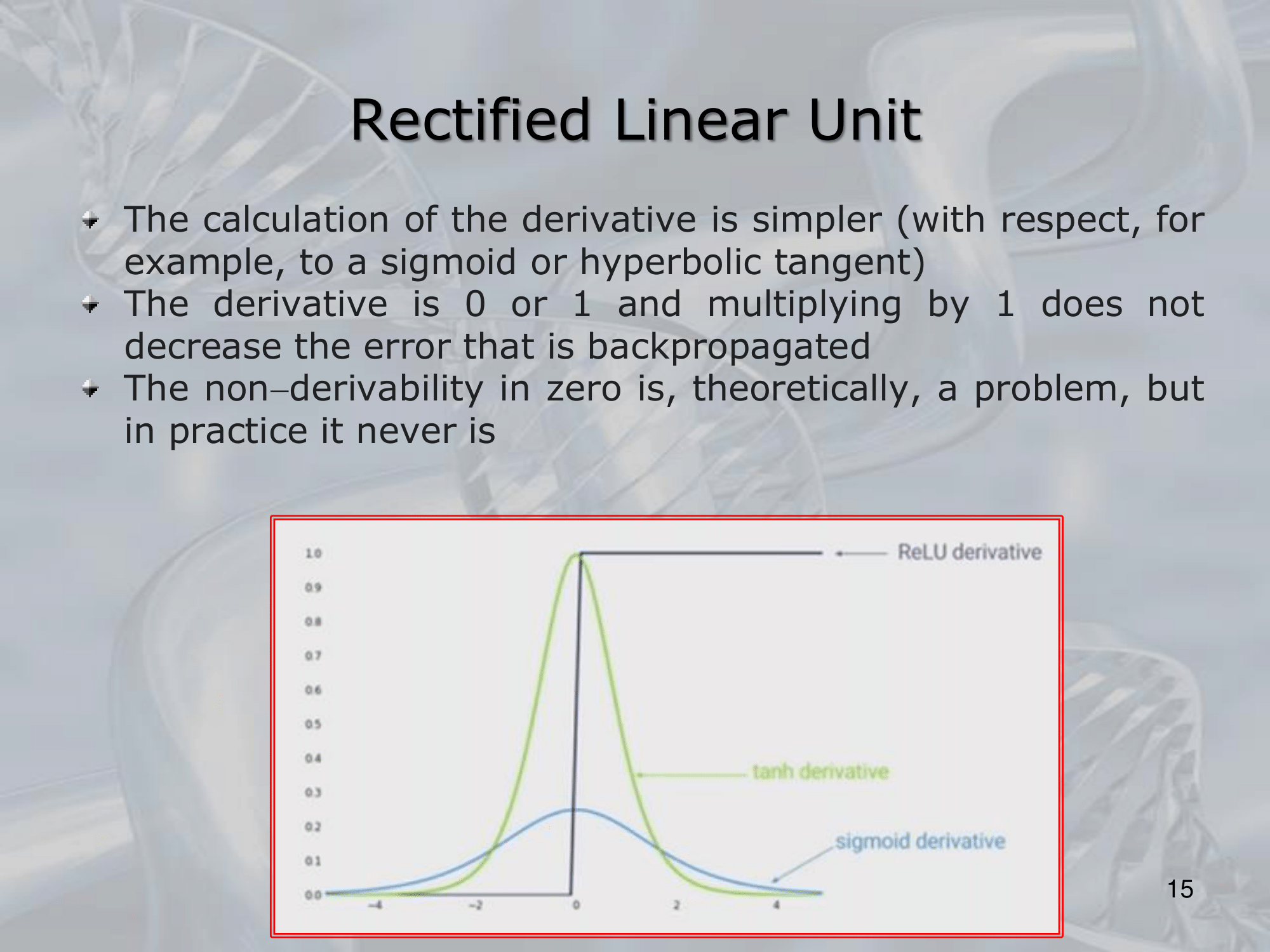
After each convolutional layer, a non-linear activation function is applied to the output, typically ReLU (Rectified Linear Unit), which helps to introduce non-linearity into the network and make it capable of learning more complex features.
Pooling layers are often inserted between convolutional layers to downsample the feature maps and reduce the dimensionality of the input. The most common type of pooling is max pooling, which selects the maximum value from a small rectangular region of the feature map and passes it to the next layer.
Finally, the output of the last convolutional layer is flattened and fed into one or more fully connected layers, which perform a classification or regression task on the extracted features.
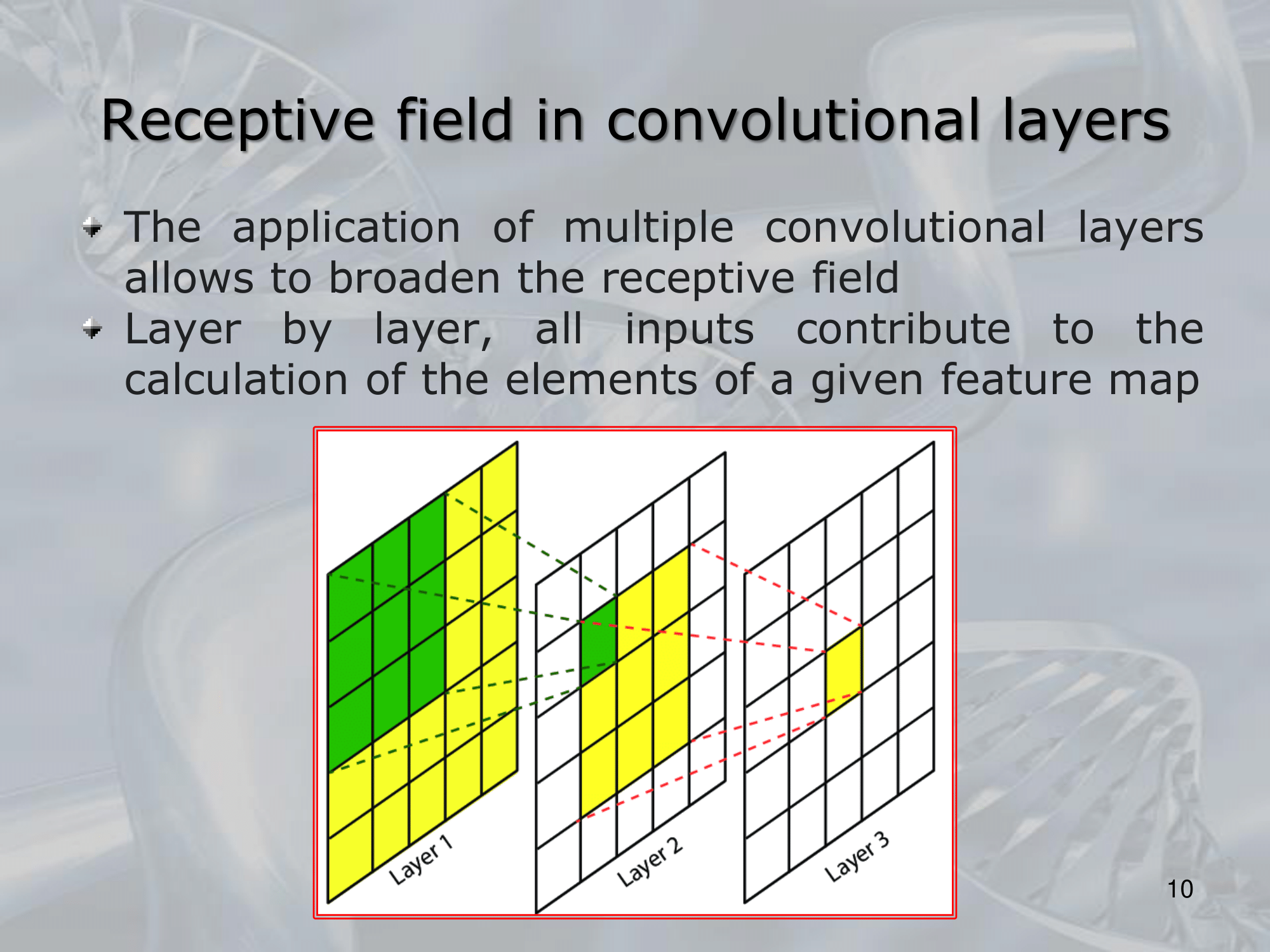
Overall, the key idea behind CNNs is to learn a hierarchical representation of the input image, where each layer extracts increasingly complex features from the previous layer’s output, leading to high-level features that can be used to make accurate predictions.