Supervised Learning: Non-Parametric Estimation
Up until now we have always made assumption on the form of the PDF when estimating the probability .
To sum it up:
- Our objective is to estimate
- We don’t want to make any kind of assumption on the underling PDF of the data.
We can opt for one of three options:
- Estimate the pdf using the data we have available, then calculate using the formula above.
- Calculating directly using the data, which is the result of a chosen discriminant function.
- We first reduce the dimension space of the data, , then we estimate the probability using one of the other two methods ( or ), but this time we make it using Computing turn out to be easier than computing
Original Files


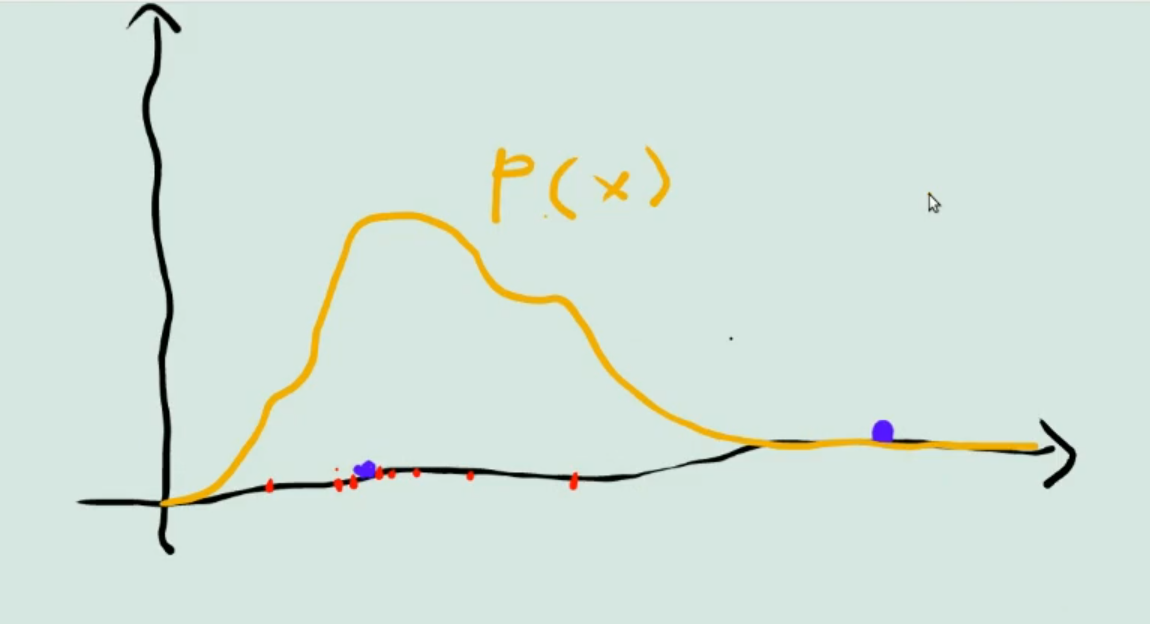
The idea of projecting on is the same as in the Unscented Kalman Filter and the Particle Filter, creating a pdf given some data: