Fast Recap:
-
Autoencoder
- An ANN where the training data is defined as
-
Normal Use of an Autoencoder
- Let be the original feature space, , so our goal is to train an ANN to realize the function .
- From we define the training set for our autoencoder: and then train our autoencoder.
- We remove just the output layer from our autoencoder and obtain a new function such that , using this function on the input we obtain a new set
- We train a new MLP via backpropagation on and we obtain the function .
- We mount the two MLP (autoencoder and new MLP) on top of each other and obtain the function
- We can tune the completed MLP via backpropagation on the original data set , if necessary
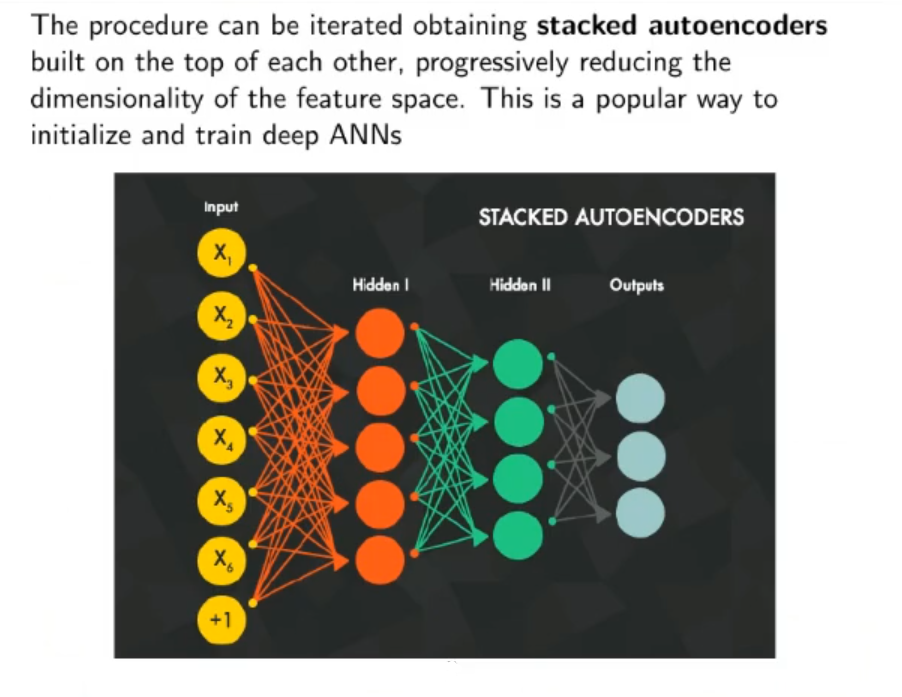
- We can iterate this process stacking even more autoencoder at the beginning of the whole MLP
Recap:
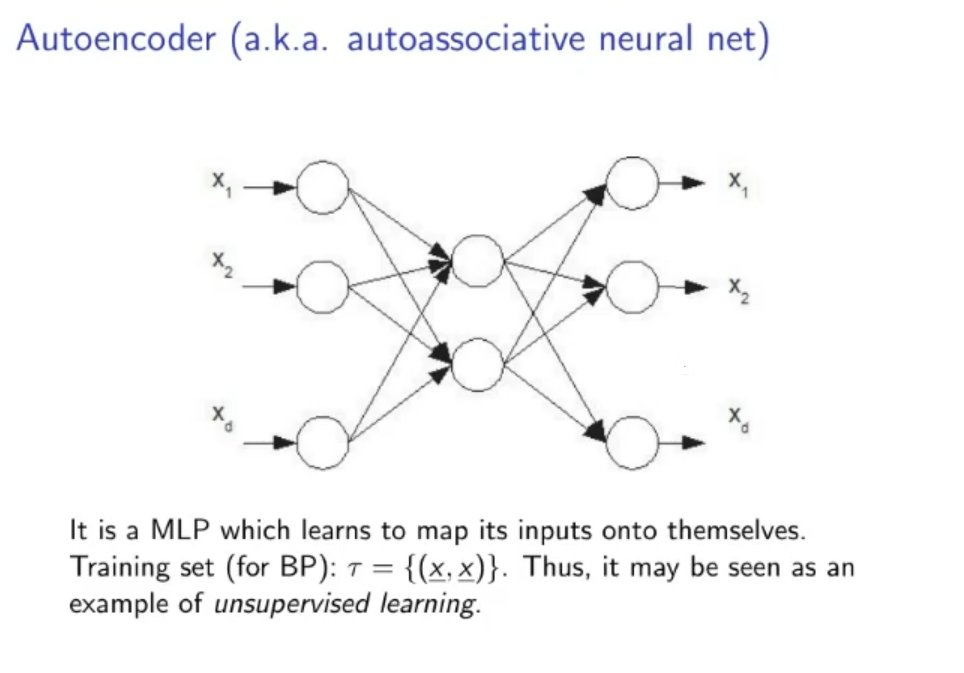
Autoencoder (Auto-associative Neural Net):
Train a neural network such that it has at least 1-hidden layer, with dimensions of the last hidden layer smaller than the dimension of the input layer, also it’s data set is a supervised set that has same input and output
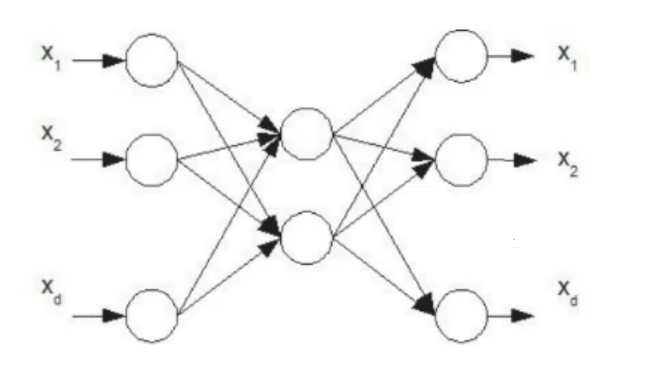
If we separate the output layer what we end up with is an encoder and a decoder for our input data.
- We can use just the encoder and attach it to the beginning of a new NN and use it to reduce the dimension of the input data.
- We can use just the encoder to reduce all our input data and then use the new input with faster training time (smaller dimensions)
- We can use the whole autoencoder as a noisy filter for our data, worsening the training data to obtain a more general model.
Tho the general approach of what we want to do is:
- Let be the original feature space, , so our goal is to train an ANN to realize the function .
- From we define the training set for our autoencoder: and then train our autoencoder.
- We remove just the output layer from our autoencoder and obtain a new function such that , using this function on the input we obtain a new set
- We train a new MLP via backpropagation on and we obtain the function .
- We mount the two MLP (autoencoder and new MLP) on top of each other and obtain the function
- We can tune the completed MLP via backpropagation on the original data set , if necessary
- We can iterate this process stacking even more autoencoder at the beginning of the whole MLP
ANNs : Patter Recognition and Probability Estimation: We can use an MLP as a non-parametric estimator for pattern recognition in 2 ways:
- Use MLPs as discriminant function: Train them via backpropagation on a set labeled with outputs.
- Probabilistic interpretation of the MLPs outputs.
NOTE: The MLP output may be interpreted as a probability if and only if it is constrained within the range. This is guaranteed if sigmoid activation function are used. We also need to assert that the sum of all outputs equal to 1, this is done if we let: Where: is the -th ANN output over the current input .
Or we can use the SOFTMAX normalization:
Theorem: Lippmann, Richard: If we reach the global minimum using targets and the right MLP architecture, we are guaranteed that the MLP obtained this way is the optimal Bayesian Classifier, as long as the class-posteriors are continuous.
In practice, using backpropagation on real world data we will never find the global minimum.
Original Files:
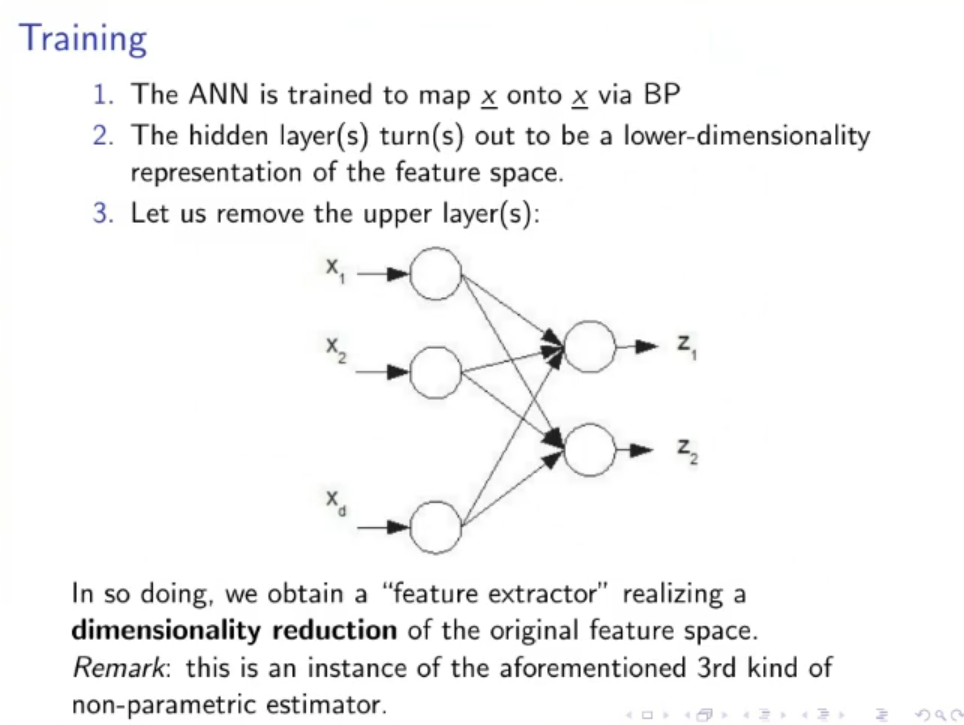

NOTE: We can use this to worsen the data to use in the training test, so to make a more robust model.