Fast Recap:
-
Main Supervised Learning Tasks:
- Function approximation: .
- Regression (linear or non-linear) : , where is the multivariate gaussian noise.
- Pattern classification: .
-
Universality of MLP:
- A non-linear MLP is very flexible
- According tho the theorem of Universality of MLP, an MLP with a hidden layer of sigmoid function an and a linear output is a universal machine.
-
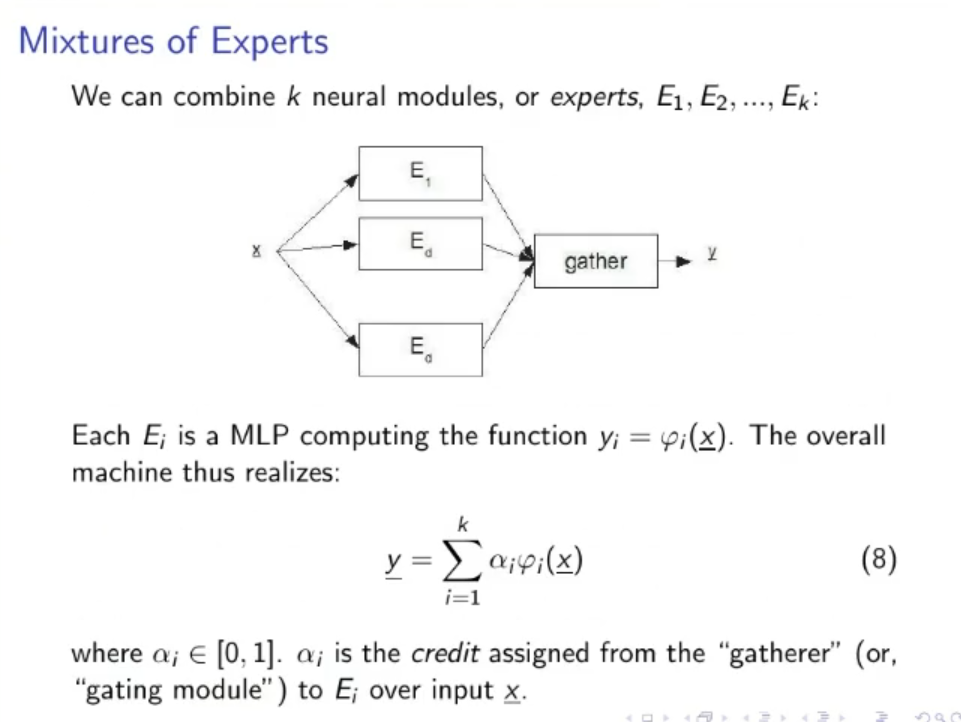
Mixture of Experts:
- A neural module can also be called an Expert.
- A neural module or expert realizes a function.
- Then a Gather assigns credit to each expert (how much a neural module is reliable)
-
Normal Uses of the Mixture of Experts:
- Divide et Conquer: The feature region may be partitioned and each partition given to a different expert, usually when used this approach the gather will give a credit of to only one expert at a time (the one that knows about the current region) and all the the other credits will be equal to .
- Overlapping regions: Each expert will express a “likelihood” of being competent over any input , the gather will assign credits according to a pdf under the condition that and imposed during both training and test.
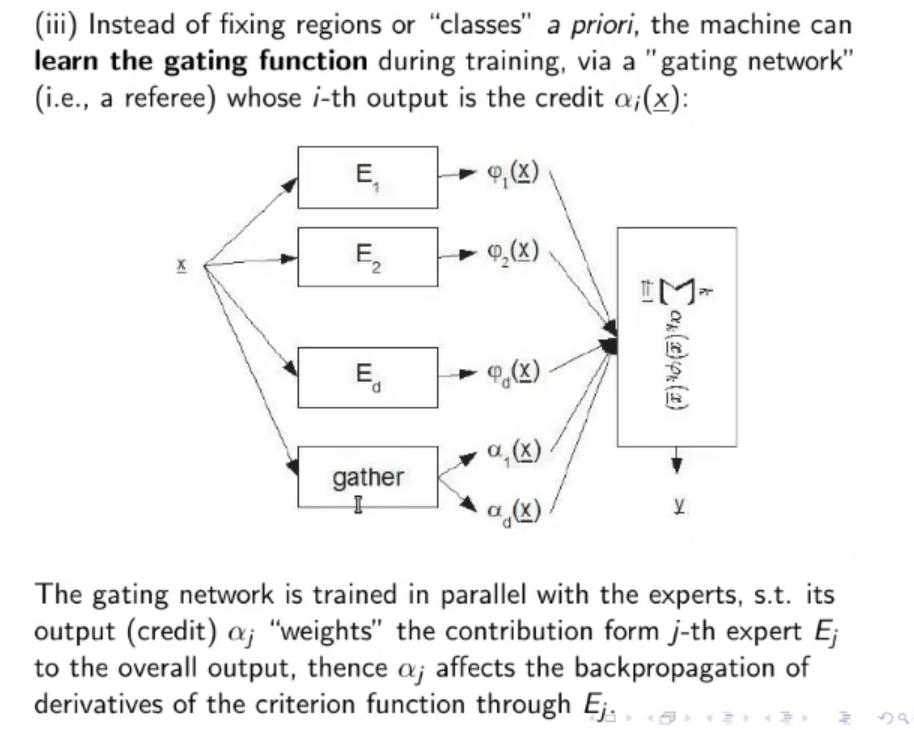
- Training the whole Mixture of Experts: Instead of training each expert separately, we can train the whole model including the Gather, which can learn automatically the values of all credits (). The Expert and the Gather are trained in parallel.
Recap:
Main Supervised Learning Tasks: A supervised MLP learns a transformation which in principle, may be applied to :
- Function approximation: .
- Regression (linear or non-linear) : , where is the multivariate gaussian noise.
- Pattern classification: .
2-Class Classification: Depending on how we descrive the model, we might obtain a liner or non-linear classifier. This is heavily influenced by the number of hidden layers in the MLP:
- If we have no hidden layers and a sigmoid activation function, the model will result into a linear classifier.
- While if we have at least 1 hidden layer (still considering sigmoid activation functions) the model will be non-linear
Universality of MLP: A non-linear MLP is very flexible:
According tho the theorem of Universality of MLP, an MLP with a hidden layer of sigmoid function an and a linear output is a universal machine.
Given an unspecified number of neurons, and an unspecified method to learn the correct values of the weights, an MLP with just 1 hidden layer and sigmoid functions can generalize any function .
Mixtures of Experts: A neural module can also be called an Expert. A neural module or expert realizes a function.
Then a Gather assigns credit to each expert (how much a neural module is reliable), result in the final equation:
Where:
- is the credit assigned from the Gather
- The feature region may be partitioned and each partition given to a different expert, usually when used this approach the gather will give a credit of to only one expert at a time (the one that knows about the current region) and all the the other credits will be equal to .
- Overlapping regions: Each expert will express a “likelihood” of being competent over any input , the gather will assign credits according to a pdf under the condition that and imposed during both training and test.
- Instead of training each expert separately, we can train the whole model including the Gather, which can learn automatically the values of all credits ()
Original Files: