Fast Recap:
Recap:
Validation of Classifiers: Given our labeled data we divide it in training set , test set and validation set , then:
- We select a model .
- Using the training set we estimate .
- After defining a cost function we calculate the evaluated error on the validation set .
- If is not good, we restart from point ( or )
- We do the final evaluation of the model error () using the test set .
“Leave One Out” Method : Used if the data sample is small and it is difficult/expensive to add data
- Let
- Loop for Use to estimate Compute and store using the model with hyperparameters
- The error is always evaluated in “new data”, data that is not in the training set and the model has not yet seen.
- At the end, all data is used both for training and testing, no data is “wasted”.
- It must be used on small data set, this method scales bad
“Many-Fold Crossvalidation” Method: Alternative to the normal method, it is based on the idea of the “Leave One Out” method, but it scales much better
- Let
- Loop for where: Create a test set with a certain percentage of still unused data. Use to estimate . Compute and store calculated on and using the newly founds hyperparameters .
Naming :
- : mean and vector mean
- : variance and covariance matrix
- : parameter vector, for example:
- : classes, for example the gender (male/female) we want to identificate.
- : weight
- : bias
- : data, could mean data in input or training data.
- a set of data, it usually used to indicate the training set. We could find where refers to the data of a single class , and it is given according to the distribution .
- : set of data belonging to the test set .
- : set of data belonging to the validation set.
- : number of samples used as the training set
- : real probability that , the data or variable we want to classify belongs to/is identified as the class (~ex.: in reality the percentage of male and female is ).
- : estimated probability of (~ex.: we estimate that the the percentage of male and female is , tho this is not actually true).
- : discriminant function of class , usually it is defined as: (in the linear case)
- : decision rule, a simple decision rule could be:
Original Files:

Referring to the second “Note*”*:
- : real probability that , the data or variable we want to classify belongs to/is identified as the class (~ex.: in reality the percentage of male and female is ).
- : : estimated probability of (~ex.: we estimate that the the percentage of male and female is , tho this is not actually true).
- : estimated error probability for the class .





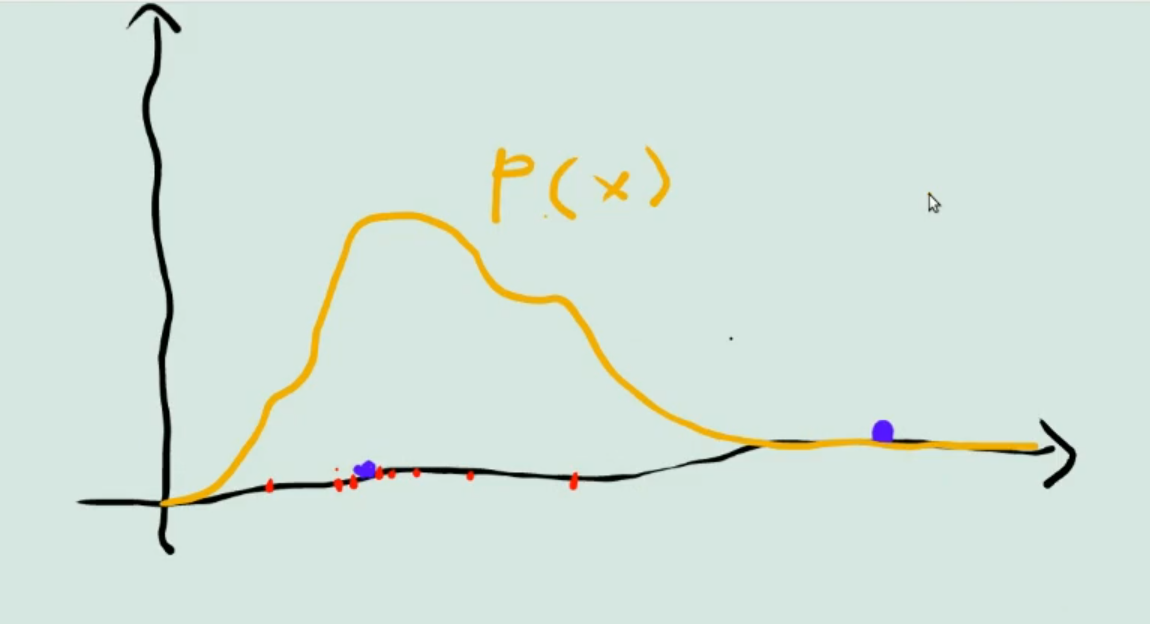
The idea of projecting on is the same as in the Unscented Kalman Filter and the Particle Filter, creating a pdf given some data: