Fast Recap:
Recap:
Density Estimation:
==MEANING of “Density Estimation” : Estimating PDFs from Unlabeled Data==
Has long been a major issue in patter recognition and machine learning. It is relevant to:
 The problem is difficult and still open
“One cannot guarantee a good approximation using a limited number of observation”
The problem is difficult and still open
“One cannot guarantee a good approximation using a limited number of observation”
Drawbacks of Statistical Approaches:
Parametric vs. Non-parametric techniques


ANN (Artificial Neural Networks) for Density Estimation:

(PNN) Parzen Neural Network:
Algorithm:

 (The solution listed as are all solution to the problem)
(The solution listed as are all solution to the problem)



Also in the PNN algorithm it is recommended to normalize data within a zero-centred meaningful range (meaningful range means not too little not to big, to be distinguished from the small zero-center range used in ANN with sigmoid activation function.
This is especially helpful to:

***If we know $X$ we can upgrade the PNN training algorithm***: ![[Pasted image 20220821195854.png]]
***Architecture Selection***: ![[Pasted image 20220907165230.png]]
TODO WHAT??

Use of PNNs for pattern classification:


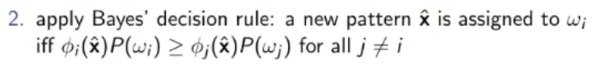

Complexity:

TRAINING COMPLEXITY*:

TEST COMPLEXITY:

Comparison of training and testing complexity with SVMs (TODO ) and with PW (Parzen Window) and -NN (-Nearest Neighbour)
training comparison
 testing comparison:
testing comparison:
 To sum it up:
To sum it up:

Modelling Capabilities:

Definition of “Interesting PDFs”:
nonpaltry pdf:

Theorem:

Original Files:







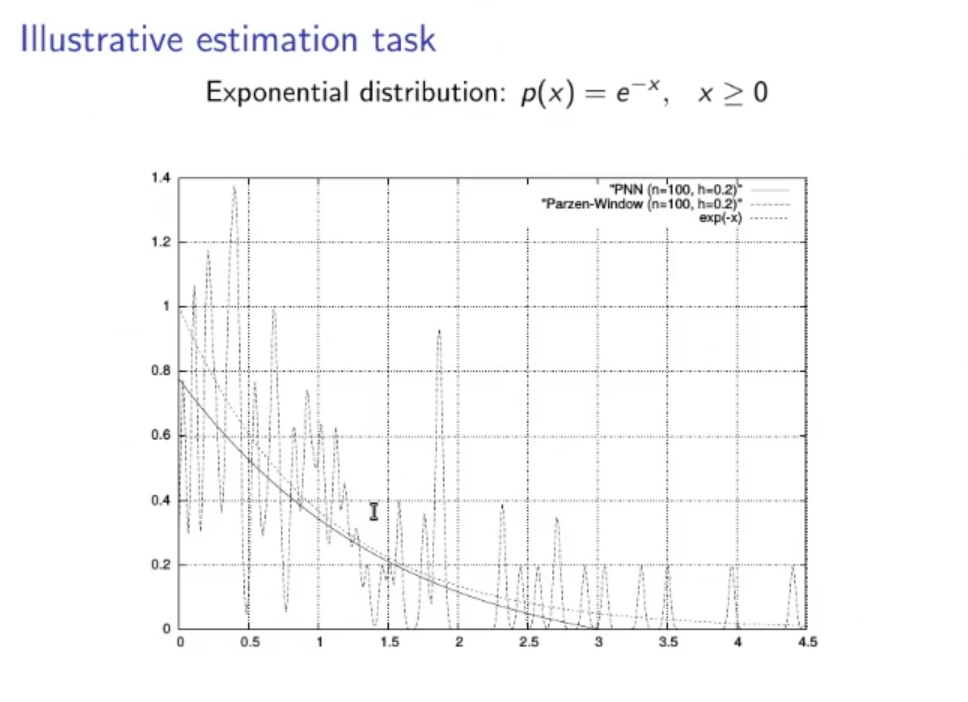
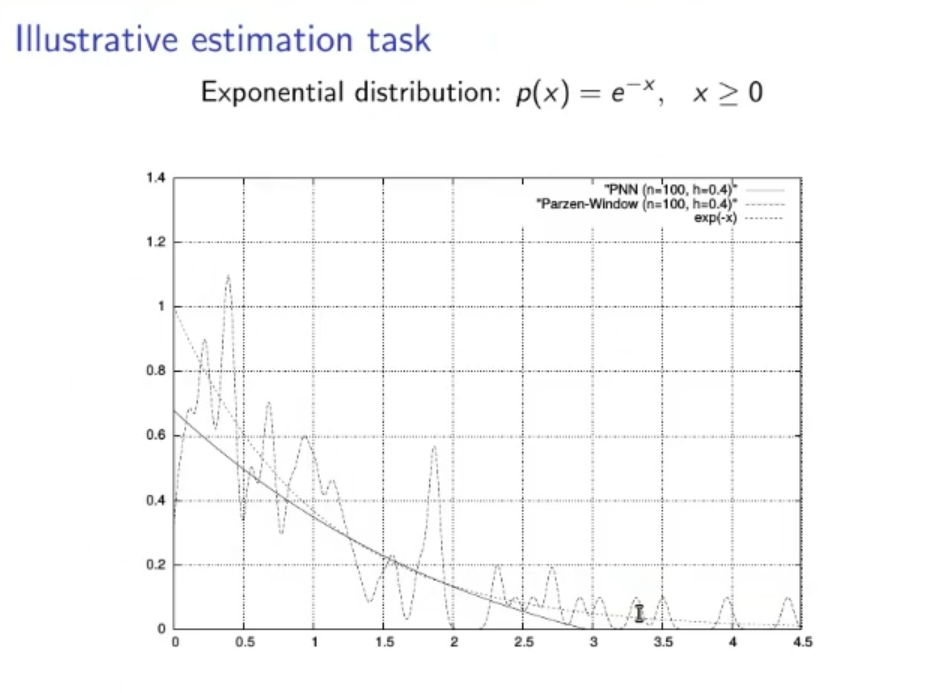
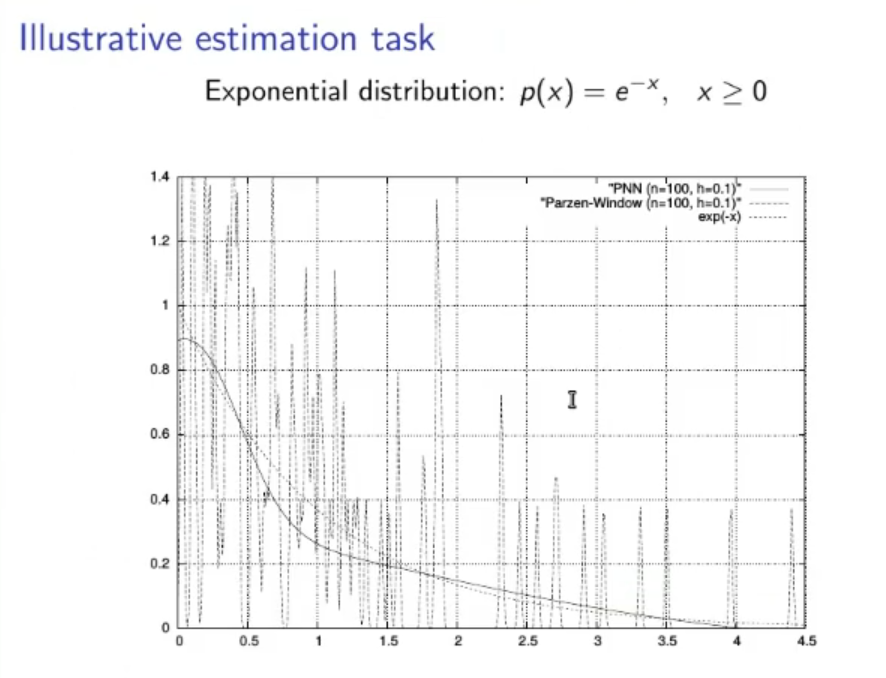
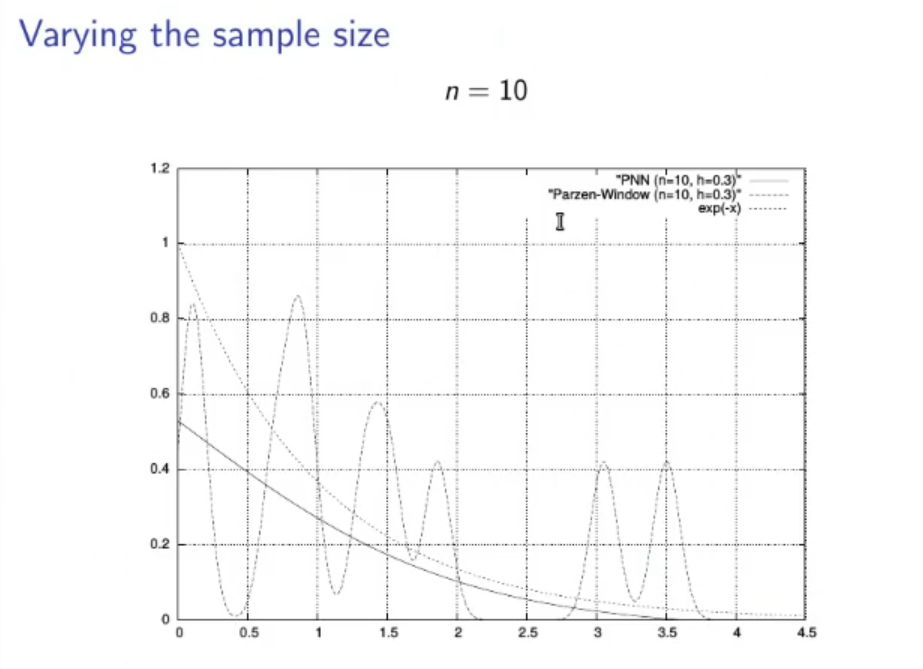
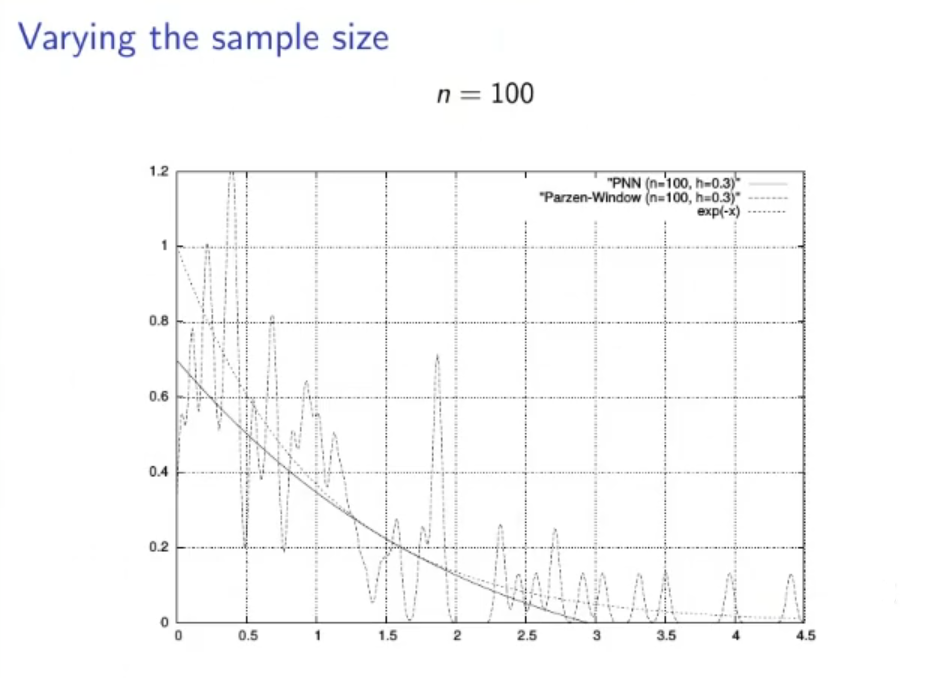
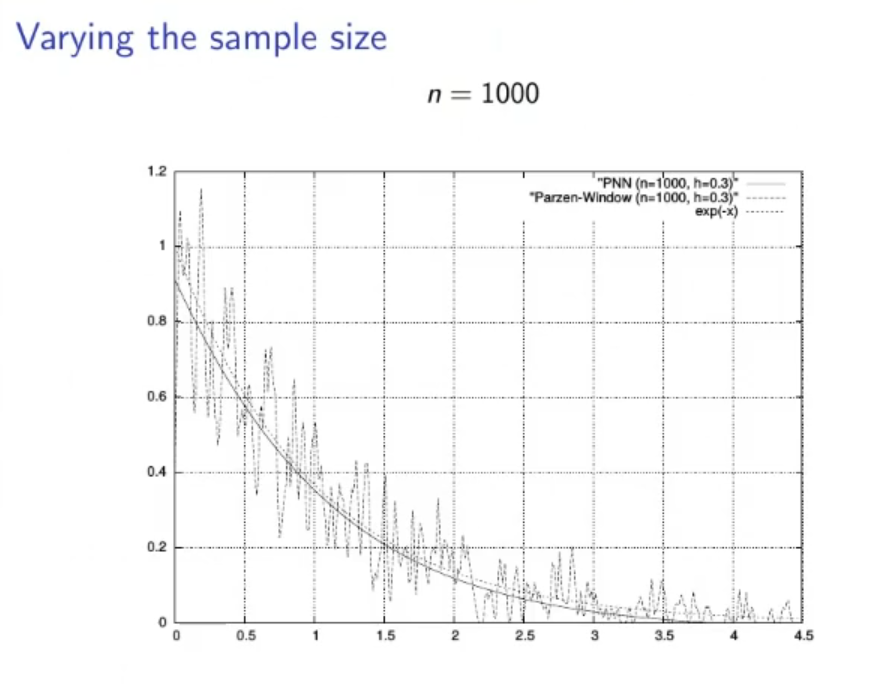
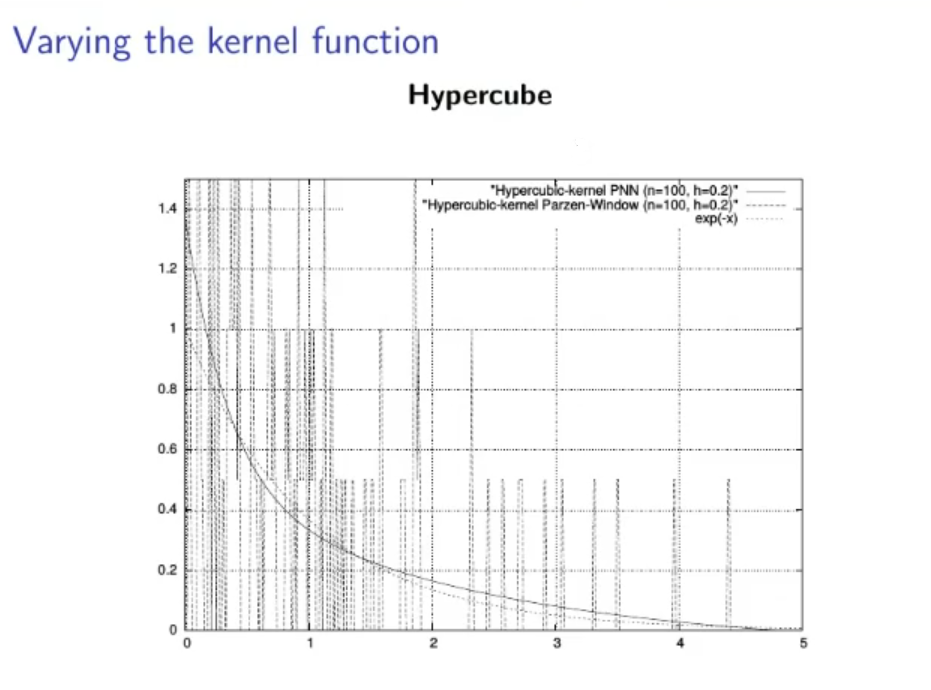







(Not to study):