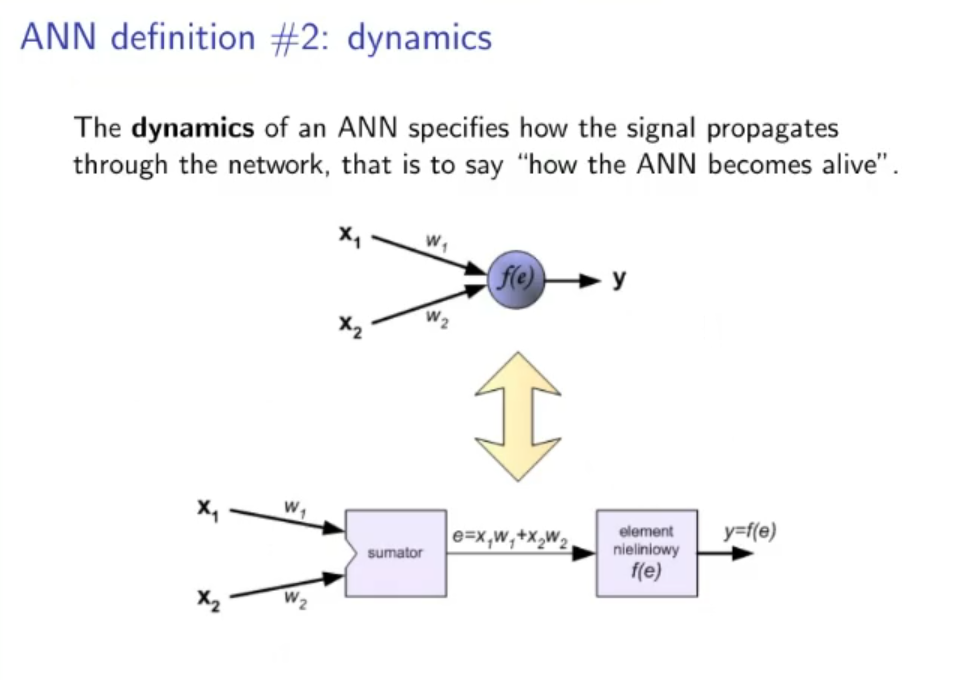
Fast Recap:
Recap:
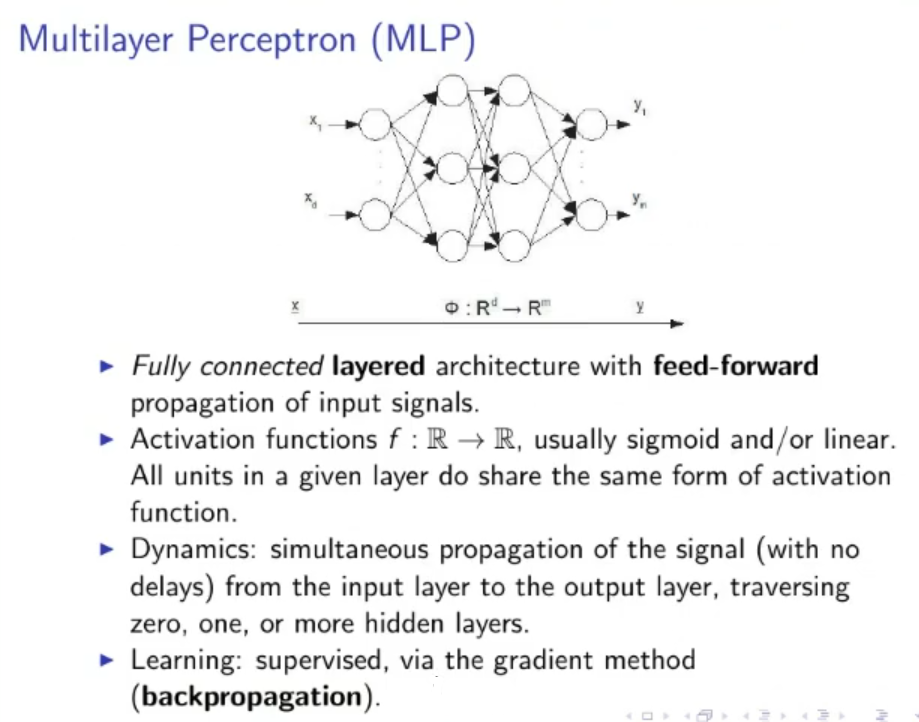
Multilayer Perceptron (MLP):
- Fully Connected layered architecture with feed-forward propagation of input signals.
- Activation Functions are usually sigmoid and/or linear
- Dynamics: simultaneous propagation of the signal with no delays, from the input layer to the output layer, traversing an arbitrary number of hidden layer (even hidden layers is acceptable)
- Learning: supervised, via the gradient method (backpropagation)
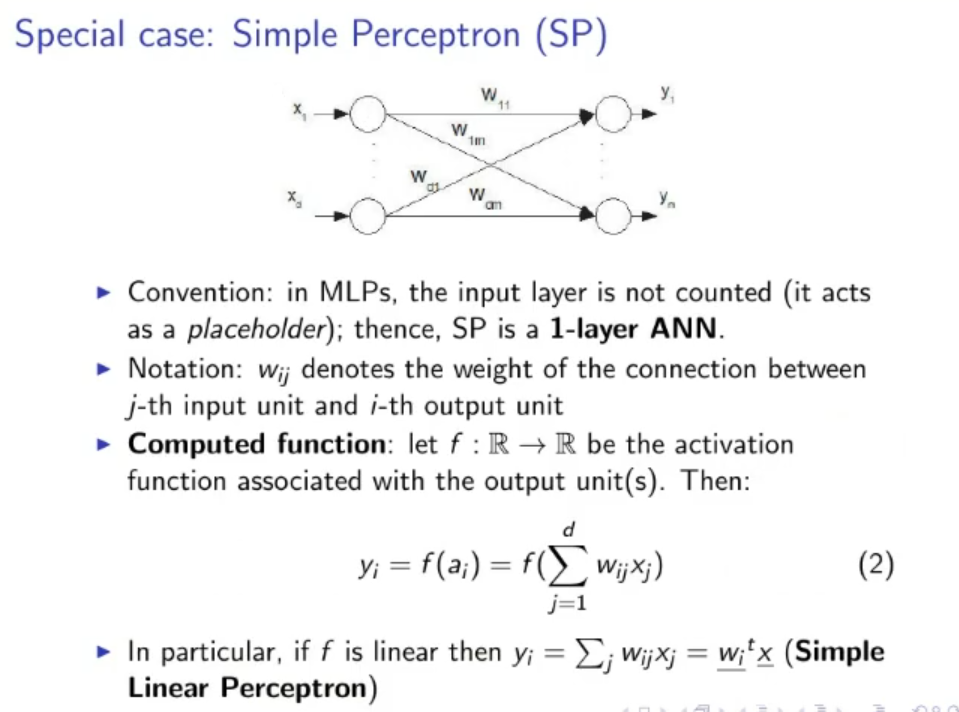
Special Case: Simple Perceptron (SP):
- Convention: The input layer is not counted, it acts as a placeholder, therefore the SP is a -Layer ANN
- Notation: ” denotes the weight of the connection between the -th input unit and the -th output unit
- Computed Function : let be the activation function, then:
In particular if is linear then: Which is called Simple Linear Perceptron.
Original Files: