Fast Recap:
Recap: Mixture of Gaussian Components: A GMM (Gaussian Mixture Model) is a mixture density having form:
With the following component densities:
Whose gradient w.r.t. (whit respect to) parameters is:
From the previous lecture we have seen that the condition to be respected is:
So we will have that, since :
But there is a problem:
The formulation is circular: to calculate we need to know , we thus resort to the following iterative algorithm:
And we iterate for up to , where is decided arbitrarily.

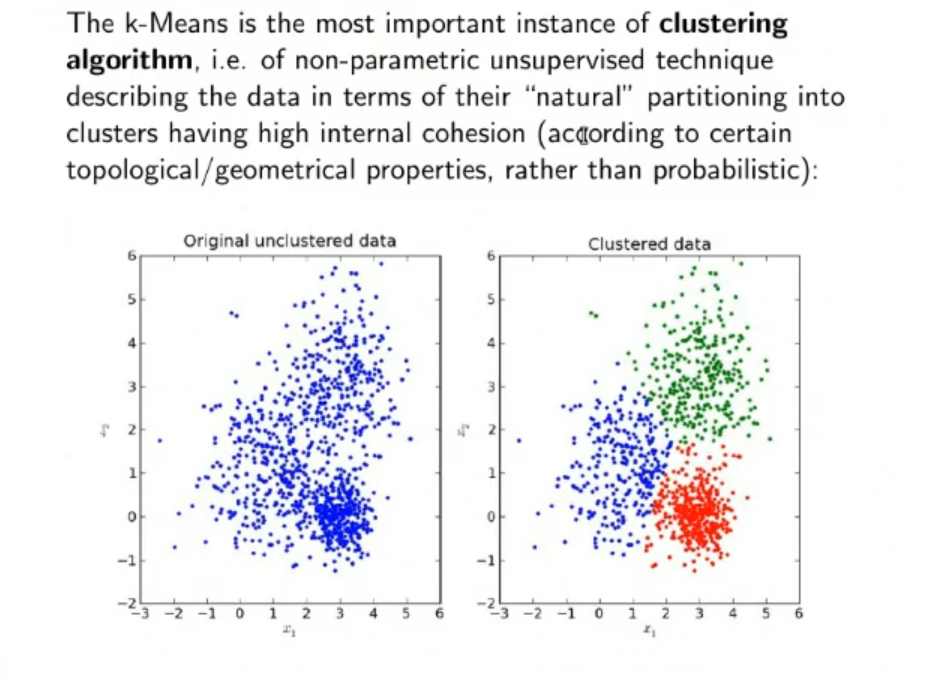
Unsupervised Non-Parametric Estimation: Clustering
Update equation for :
.png)
.png) The formula just says that given:
The formula just says that given:
- classes () each with a vector of parameters, in this case just the evaluated mean ()
The probability that belong to class is if and only if the evaluated mean is the closest to according to the Euclidean distance, with respect to all other means ( for )
⇒ So: is just or , this simplifies the calculation.
k-Means Clustering Algorithm:
- Fix initial arbitrary (~ex.: random) values: .
- Assign each (for ) to its closest mean .
- Re-calculate for applying the previous equation for updating (arithmetic mean of the pattern in cluster ).
- If then iterate from point 2., this mean:
If during the last iteration at least one value of changed, repeat.
The Problem of Data Description and are sufficient statistics (they are a complete description of our data) if and only if, our data is drawn from a Gaussian Distribution.
Otherwise they would yield a wrong data description.
To solve this problem we can use a GMM (Gaussian Mixture Model), and relying an an unbounded number of Gaussian Distribution we can describe any continuous and limited PDF. This raises two problems:
- Using an “unbounded” number of Gaussian PDFs brings complexity issues
- Also if we mix too many Gaussian PDFs the problem overfits the training data and doesn’t generalize too well.
Alternatively we can use a non-parametric technique for estimating , for example the Parzen-Window or -Nearest Neighbors, but we need to pay attention to the number of data used:
- If is small (few data), then the estimate is not reliable.
- If is big, then is over-complex, being memory-based, since must be kept in memory and involved in the calculations, this would not be a real data description.
⇒ ==Our best shot is to use Clustering algorithms.==
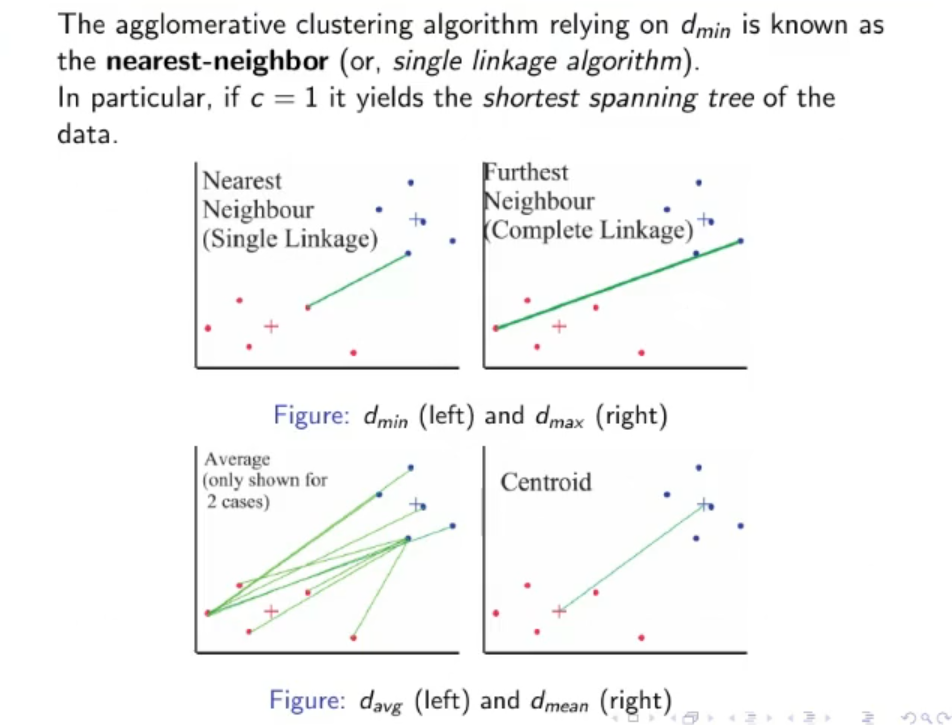
Similarity Measures
Instead of defining (the number of cluster) at the beginning we can define the maximum distance for which an element can be considered inside a cluster.
If in a single the “within-cluster distance” of 2 elements is further than , then we create another cluster and re-separate the data.
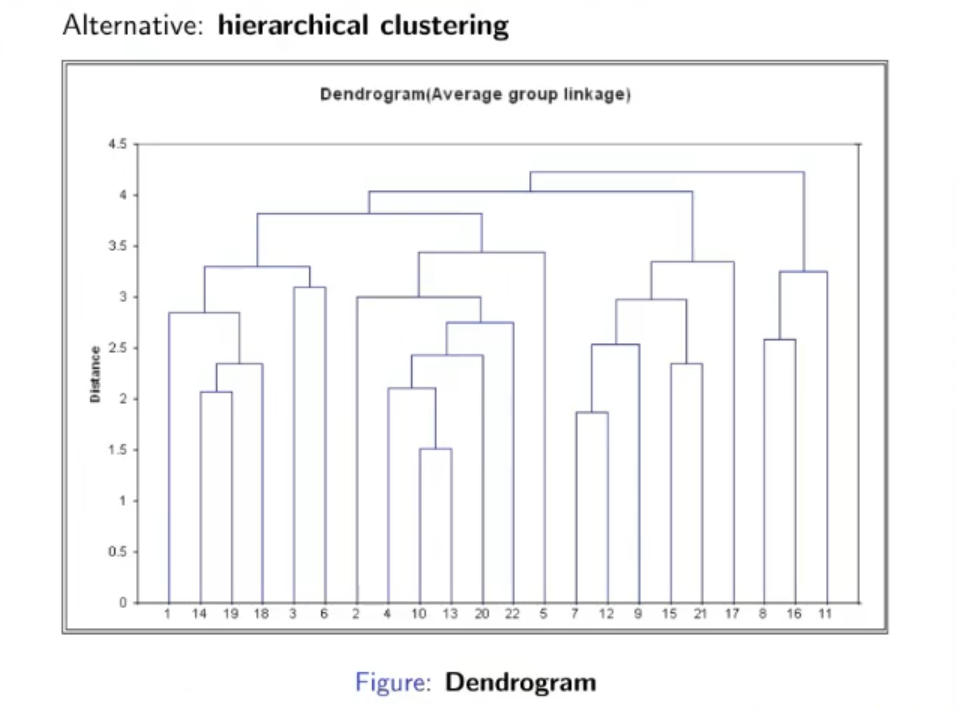
Hierarchical Clustering:
The Hierarchical Clustering has 2 families:
- Top-Bottom: Divisive Clustering (we start with 1 big cluster and separate until we have at least or clusters)
- Bottom-Up: Agglomerative Clustering, that we will see later (we start with no cluster and agglomerate data into new and previously created cluster until we at least have clusters)
Agglomerative Clustering algorithm:

Here is an example on how the algorithm works:
- We start with creating a cluster with data and since they are the closest.
- Then a new cluster with and
- We simultaneously agglomerate and into their own cluster, and add to the cluster containing and
-
Between-Clusters Distance Measures:
The most popular measures of distance between 2 clusters are:
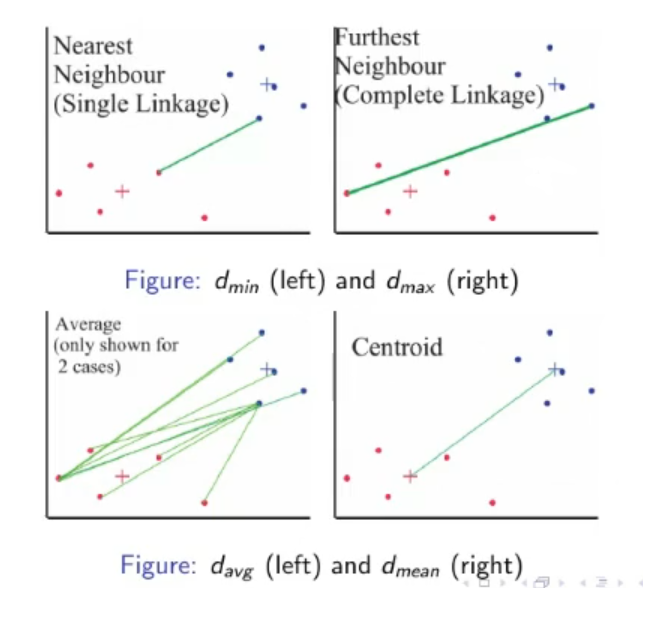
The formula for obtaining these distances are reported here:
( and are the two cluster we take into consideration)
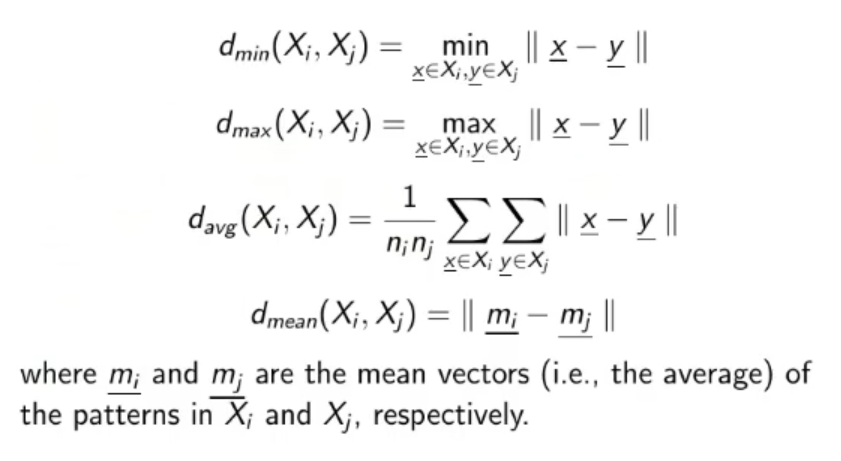
Utility of Clustering Algorithms:
- Finding the geometric/probabilistic properties of the data: (~ex.: center of mass and variance)
- Describe the data in a concise fashion
- Partitioning the data into sub-samples (useful for dived et conquer algorithms)
- Finding good initialization (the centroids) for complex models such as: GMMs with Max Likelihood, RBFs,
- Discretization of continuous features (~ex.: We can use the centroids and the number of data in each cluster to create an histograms of the data).
- Replacing original big data set with one single cluster of it, useful when working with complex algorithms like K-NN or Parzen-Window.
Original Files: