Fast Recap:
- ANN (Artificial Neural Network)
- Architecture
- Dynamics
- Training & Generalization
- MLP (Multilayer Perceptron)
- SP (Simple Perceptron)
- Learning Methods for ANN
- Batch Mode
- On-Line Mode
Recap:
-NN (-Nearest Neighbour) Decision Rule:
- Define, the pattern to be classified.
- Create an hypersphere of dimension around .
- Let the sphere expand until it includes data, where is the total number of data (training, validation and testing).
- Calculate the volume of this hypersphere.
NOTE: To have more flexibility we can define where is an hyperparameter decided arbitrarily.
Non-Parametric Decision Rule*:
- : be a supervised sample.
- : volume of the ball embracing patterns.
- : how many patterns among the pattern, belong to class .
⇒ Since we will have that the probability that will belong to class is:
⇒ Hence an estimate of is given by:
Where:
- : means the probability that will belong to one of the classes , so it is equal to .
Nearest Neighbour Decision Rule: Assign to class if and only if:
- is the nearest (according to Euclidean Distance) to , among all those in .
- belongs to class .
Where:
- : supervised sample.
- : pattern to be classified.
ALGORITHM: Search for the closest element of in , let’s say that belong to class . Then we will classify with the class .
K-Nearest Neighbor (K-NN): To not be confused with -NN (-Nearest Neighbour)
- : supervised sample.
- : pattern to be classified
⇒ Algorithm:
- Consider the patterns in that are closer to in term of Euclidean distance)
- belongs to , where is the class with the highest relative frequency within the sample taken into consideration.
NOTE: While -NN estimates a pdf, the K-NN algorithm estimates
- For , the asymptotic behaviour of the K-NN tends to be optimal (~ex.: Bayesian)
- In cases or more generally, in cases where 2 or more classes have the same relative frequency we can expand the neighbour (increasing K) until there is only one class that has higher relative frequency with respect to the others.
- The higher the value of the more accurate are the decisions taken, but it will take more time (trade-off)
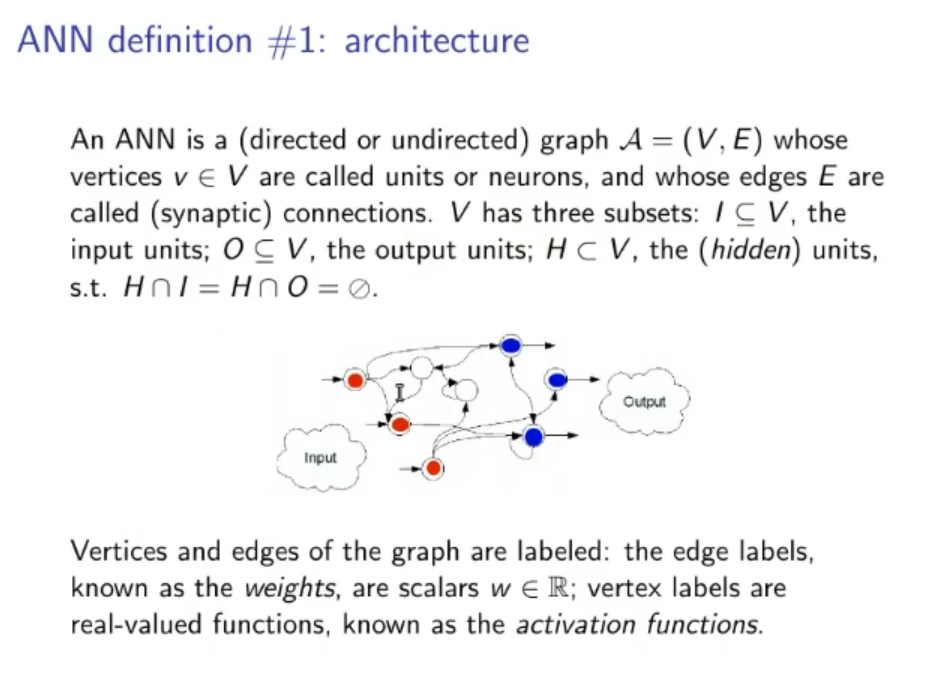
Definition of an ANN (Artificial Neural Networks): An ANN is completely specified once we define its:
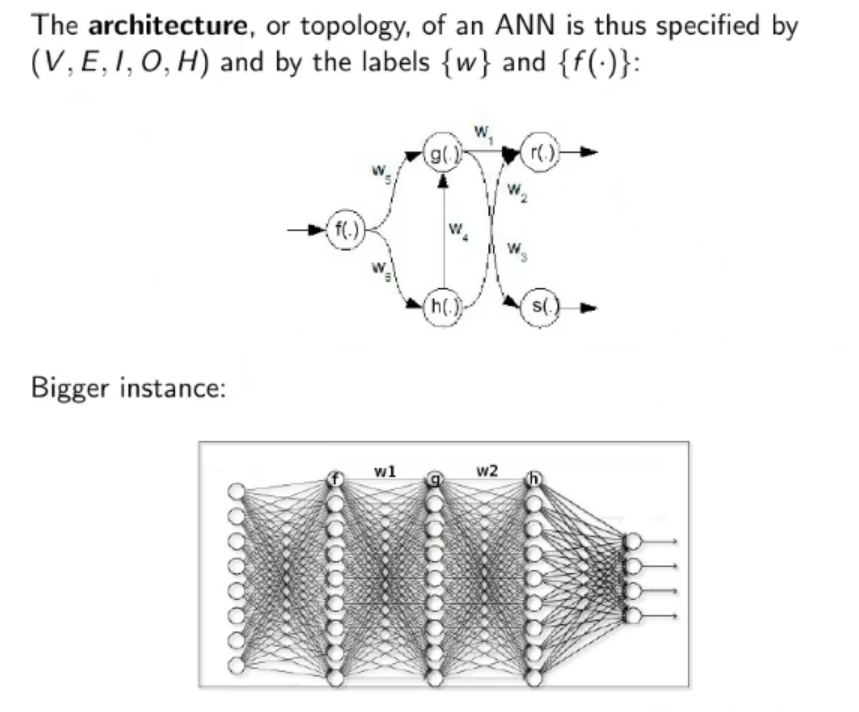
1. Architecture: An ANN is a directed or un-directed graph where each node (or vertices) is called a neuron and each arch (or edge) is called a synaptic connection, it has three subset: the input units, the output units and the hidden units. ⇒ For each node we can define an activation function ⇒ While for each arch we can define its weight. An architecture is completely defined with: Vertices, Edges, Input Units, Output Units, Hidden Units, Weights and Activation Functions.
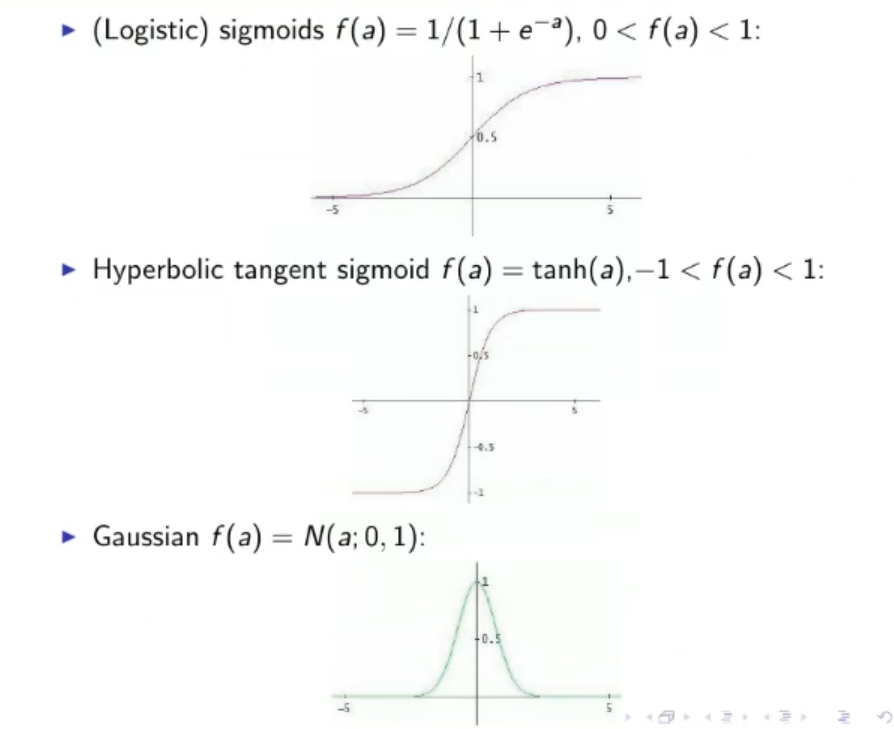
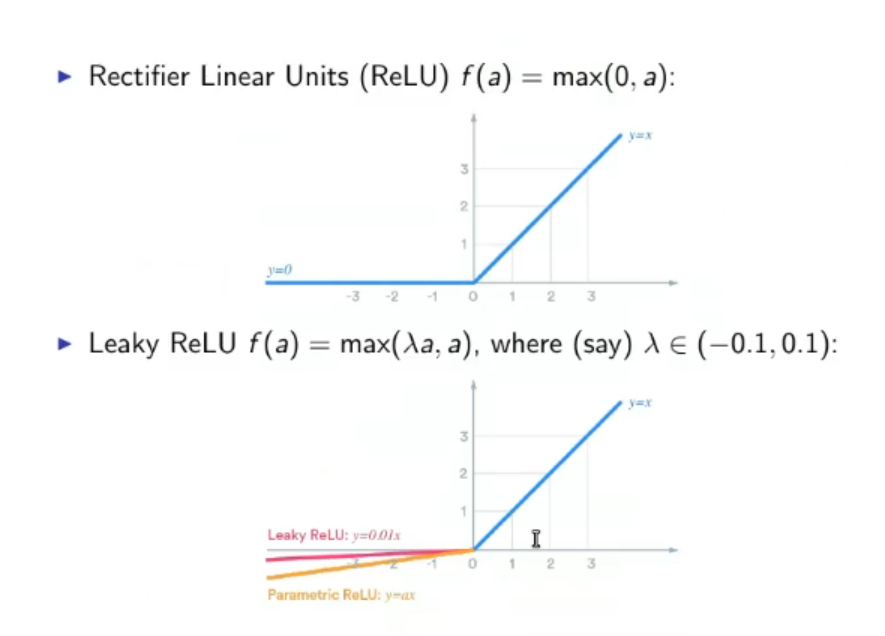
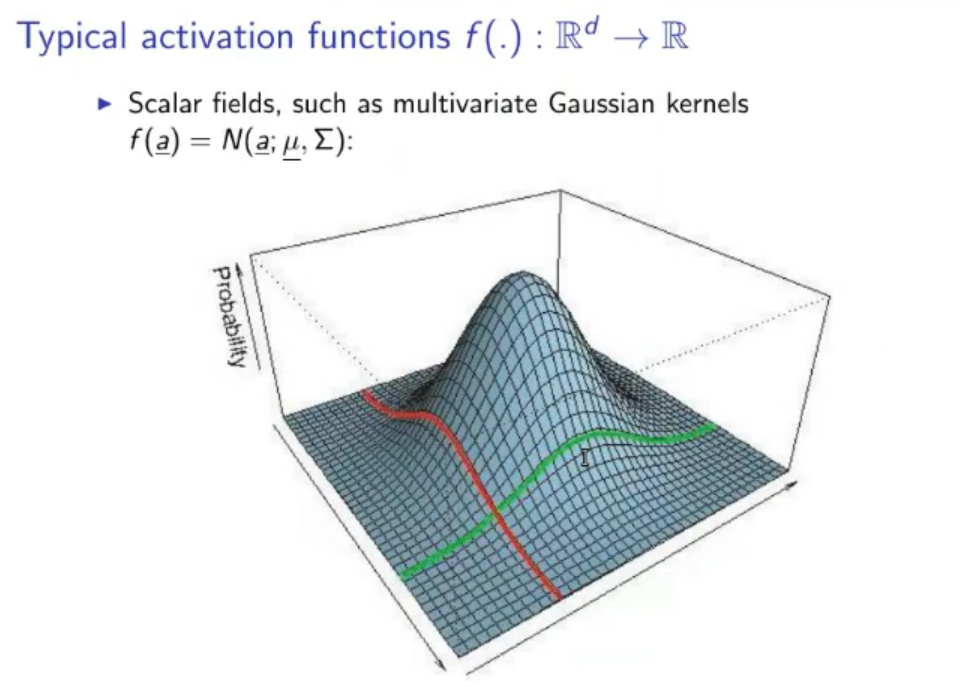
1.1. Typical Activation Functions: ⇒ Step function or TLU (Threshold Logic Units): ⇒ Linear Function: ⇒ Sigmoid function: ⇒ Hyperbolic tangent sigmoid: ⇒ Gaussian: ⇒ ReLU (Rectifier Linear Units): ⇒ Leaky ReLU:
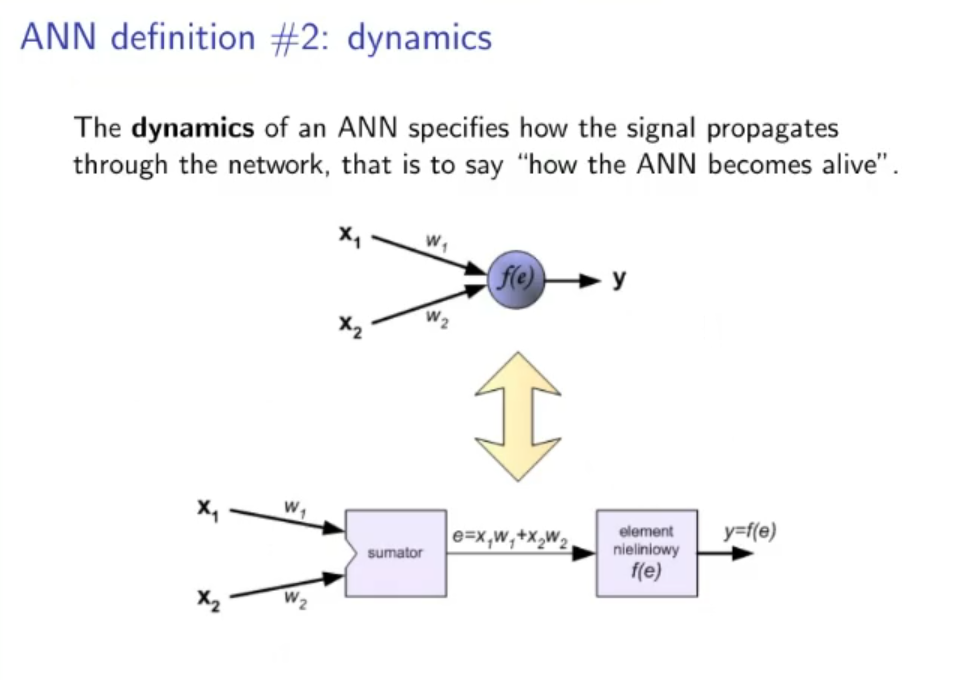
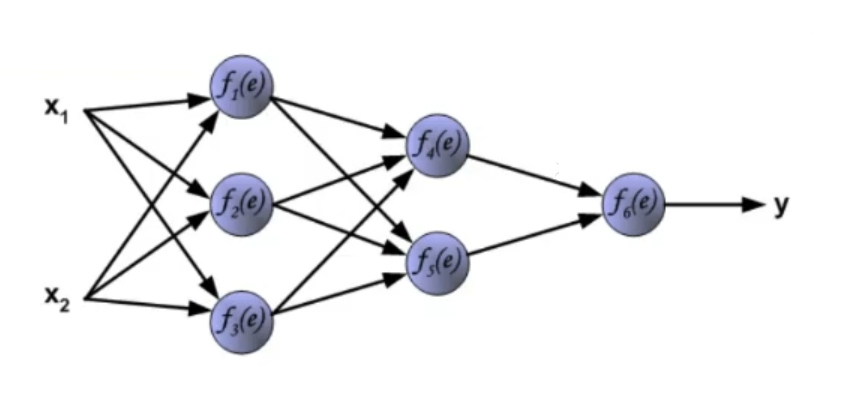
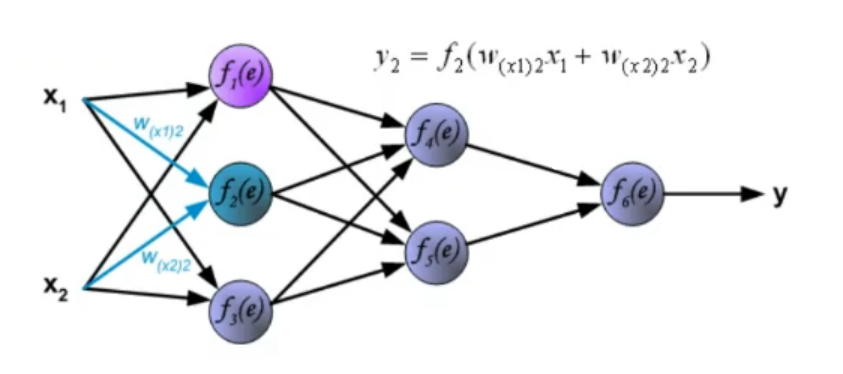
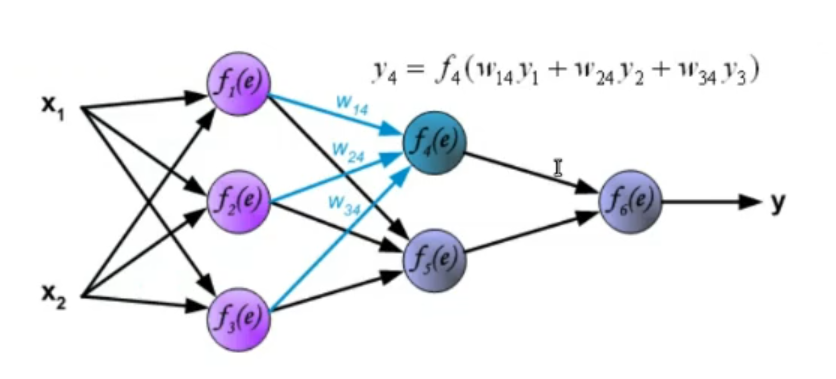
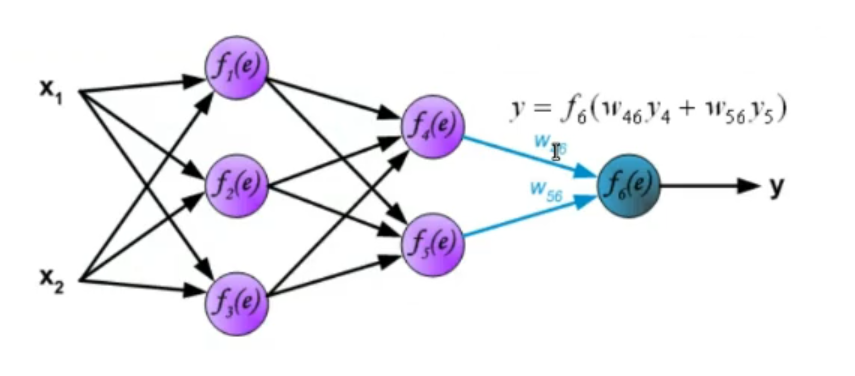
2. Dynamics: How the signal propagates. The dynamics of an ANN represent how the input data goes from start to end (how it “propagates”), we need to define how the weights interact with the data after they are processed by the activation function. ~Ex.: Let’s take input data these data will not have any transformation in the input (even this part can be changed), then they will pass through a first hidden layer where for each node the activation function will be something like:
Where: : old layers (from to ) (in this case the input) : node belonging to the new layer (in this case the hidden layer) : sigmoid function (our chosen activation function)
~Ex.:
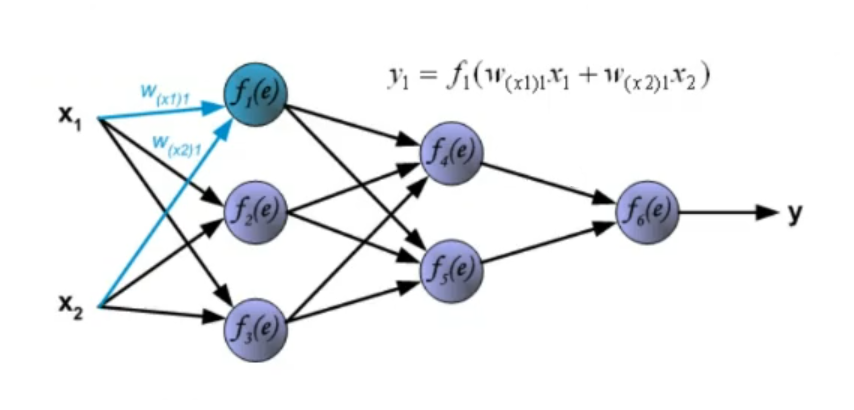
This process is then repeated until the signal reaches the output layer.
Also the dynamics also define the clock (time trigger) of the ANN, which depends on its family of networks.
NOTE: The ANN topology specifies the hardware architecture, the value of the weights it’s the software, while the ANN dynamics (the living machine) represents the running process.
3. Learning: The ANN learns from the examples contained in the training set which is a continuous-valued data sample drawn from an underlying multivariate pdf. Main learning setups: ⇒ Supervised Learning: ⇒ Unsupervised Learning: ⇒ Semi-Supervised Learning: training data are supervised, they are a set of input and output , while data are unsupervised, we know the input but not its output ⇒ Reinforcement Learning: Where a reinforcement signal either a penalty or a reward is given every now and then.
3.1. Generalization: Learning is a process of progressive modification of the connection weights, aimed at inferring the (universal) law underlying the data. Far from being a mere memorization of the data, the laws learned this way are expected to generalize new data, previously unseen, this is called generalization capability.
Original Files: