Fast Recap:
Recap:
May we use MLP as an estimate of the class-conditional PDFs? Since the output of an MLP can be seen as:
We can write:
Which is knows as scaled likelihood.
- is unknown, but can be estimated.
- Also estimates are more robust than estimates, because we need to estimate only one estimate instead of other PDFs ( : number of classes, ), also with the same logic if we estimate only we will have times more data.
- Also if changes over time (let’s say it assumes the new value ) , we can just reuse the same MLP, so no re-training necessary and use the following formula:
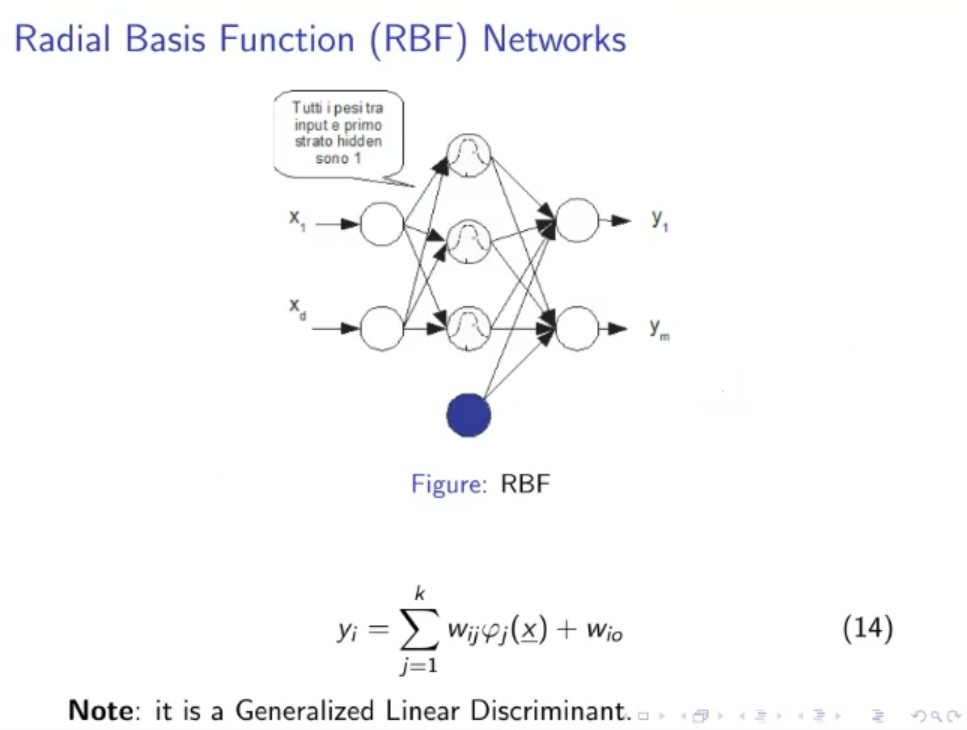
RBF (Radial Basis Function) Networks:
A generalized linear discriminant
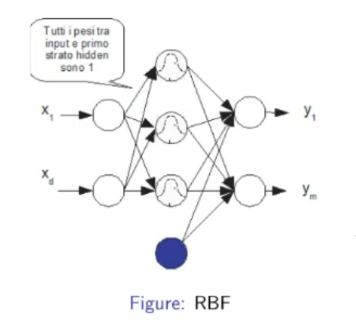
- All weights between the input layer and the first hidden layer are equal to .
- There could be a bias terms: .
- The RB Function (Radial Basis Function), or kernel is defined as:
- A simple RBF Network with just 1-hidden layer will have this form:
- RB Functions realize a mixture of Gaussian PDFs, hence they are particularly suitable for pdf estimation.
- Like MLPs, RBF Networks are “universal” approximators.
For the learning part, it’s supervised
And we usually consider 2 approaches:
- Via gradient descent over , we learn the parameters: , , and .
- and are estimated statistically, then the other parameters and are estimated via linear algebra methods (such as matrix inversion), or via the precedent method gradient descent.
NOTE: With RBF Networks we can apply gradient-ASCENT over ML (Maximum Likelihood) method in order to estimate PDFs.
The ML method only works if the weights between the last hidden layer and the output layer sum up to .
This can’t be done in MLPs because the constraint is violated, since they realize MLPs realize mixtures of activation functions that are not inherently pdfs.
Original Files: