Practical Issues and Some Insights:
- Weights must be initialized randomly and they must belong in a small interval . ⇒ If is to big, the sigmoid will saturate. ⇒ if the weights are all equals to each other then the model will not “brake symmetry” (the weight in each layer will be equal to each other, no matter the number of epochs).
- It’s a good practice to normalize the inputs, a typical choice is in the range .
- Using sigmoid function will automatically normalize the outputs in the interval .
- Regularization: Reduce the number of dimension of the model, to do this we can opt for two famous techniques: ⇒ Weight-Sharing: Some connection are forced to use the same weight, the learning for those weights () is computed by averaging the different values of the originals ⇒ Weight-Decay: Numerically smaller weights means simpler solutions:
Where: : is called the regularization term, (if the weights increase so does the cost ).
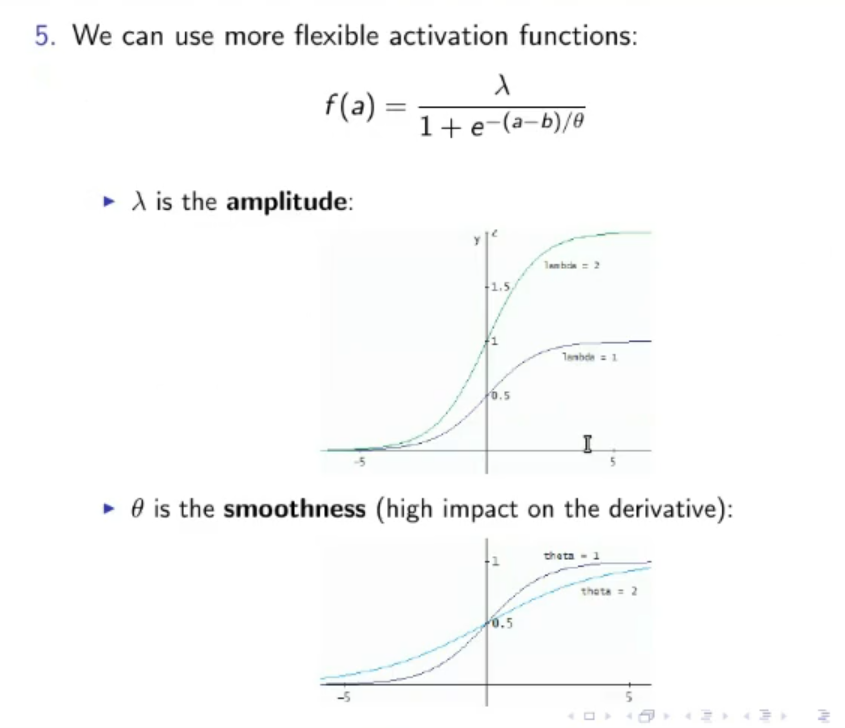
- We can use more flexible activation function, they will require more time in the learning phase, but should bring a better, faster and smaller model. For example, instead of the common sigmoid, we might opt for:
- Learning may be more stable by including a momentum term, (or inertia), in the delta rule:
Where: is the momentum rate, how much should we consider the old in the new one.
Original Files