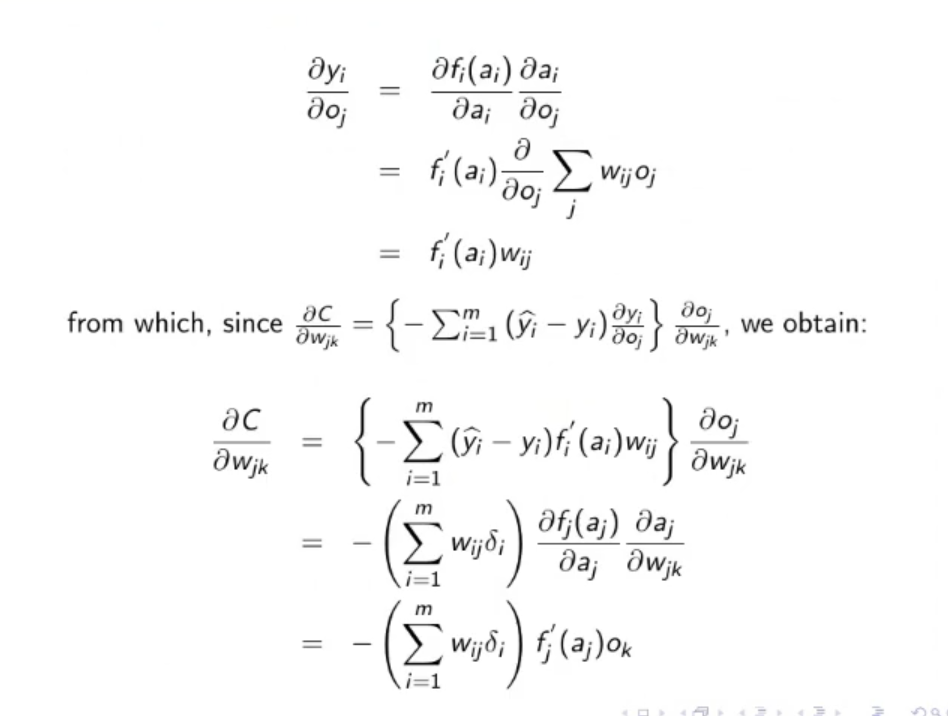Fast Recap:
- Gradient Descent
- Delta Rule
Recap:
MLP (Multilayer Perceptron) Learning Algorithm: Backpropagation:
- Batch Criterion Function:
Where:
- : is the training set (supervised)
- : weight
- : predicted output given by the ANN.
- Online Criterion Function:
The difference with the Batch Criterion is that in the online mode only one output is considered to calculate the Cost , while in the batch for each cost we consider outputs (a batch).
Gradient Descent: For a generic weight we apply the Gradient Descent:
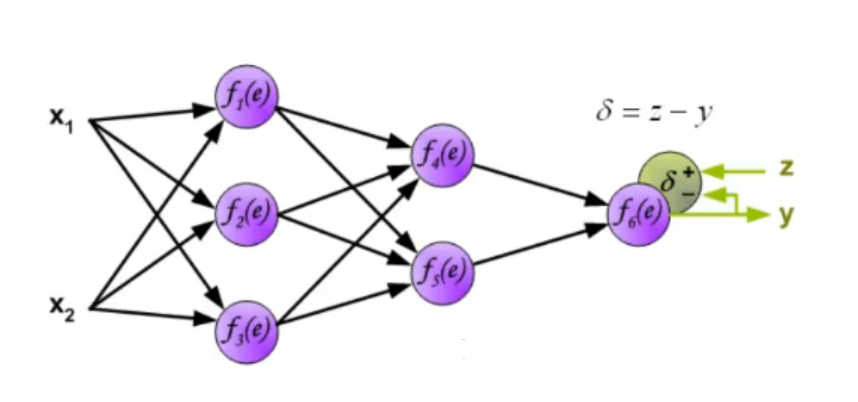
~Ex.: Online Mode, 1-Layer ANN 1-Layer ANN: 1 Input Layer, 1 Output Layer, we only have one set of weight.
- : -esim activation function
- : old layer, in this case the -esim input.
After some calculation the result is:
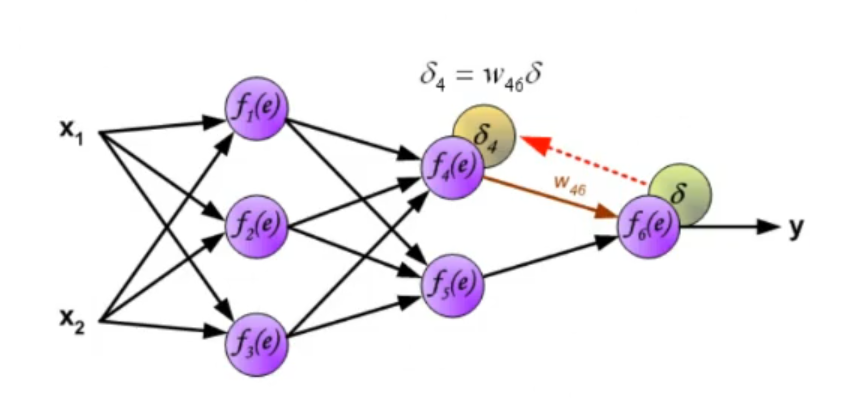
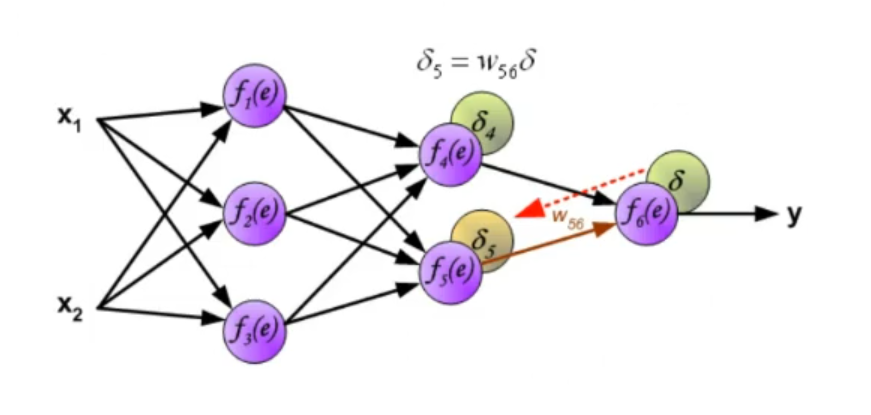
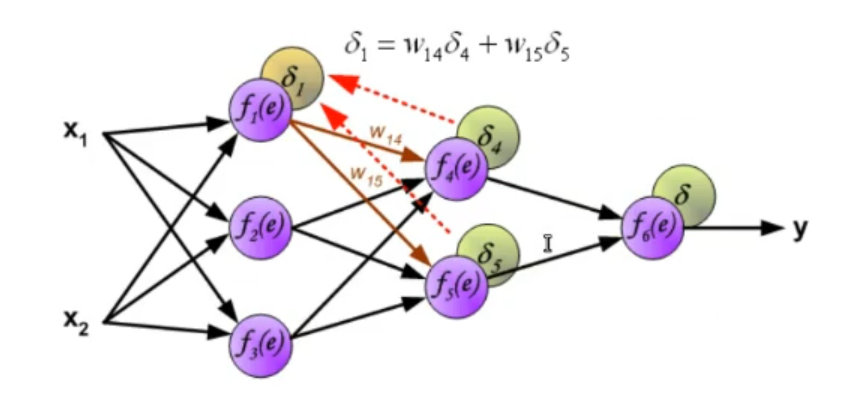
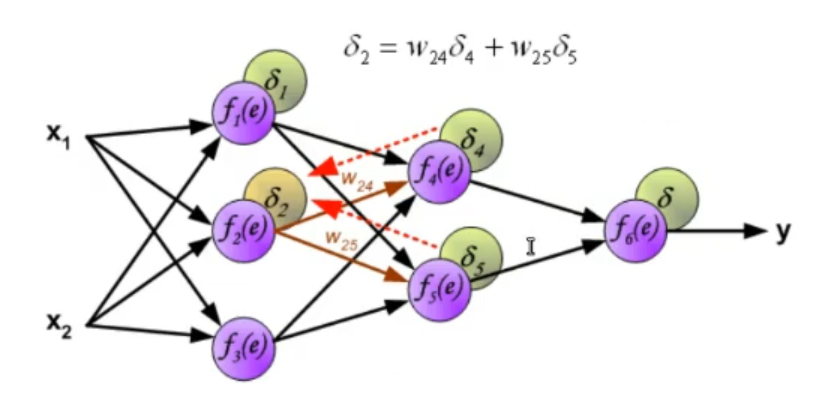
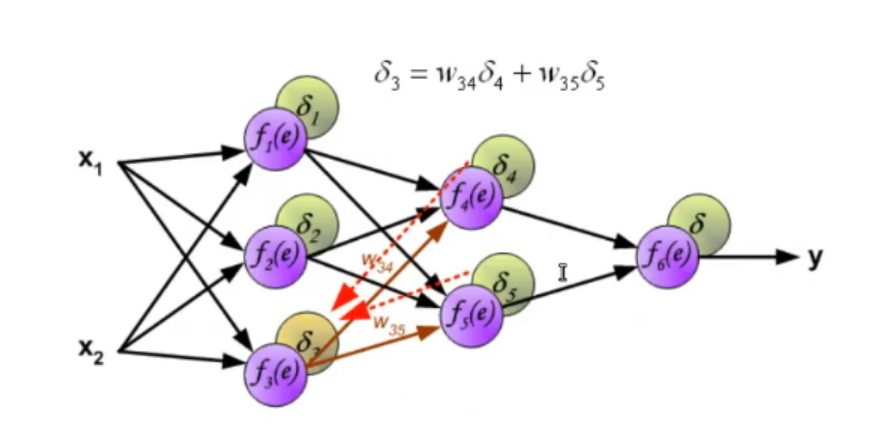
~Ex.: Online Mode, 2-Layer ANN Having an Hidden Layer adds to the computation in the last equation is not the input layer but in this case it’s the output of the hidden layer, so it depends on some weights and on an activation function. The of the output layer is:
Where:
-
-
- This is known as the Generalized Delta Rule:
- Learning is iterated for a defined number of consecutive cycles called epochs, using only the training set.
- An epoch is a cycle of application of the delta-rule over all the data in .
Original Files: