Regularization
If you are given more variables (features) than learning example, you could use the regularization algorithm to reduce linear dependent parameters, reducing their number
NOTE: The Regularization tecniche is kind of dated. Usually the number of examples is much grater than the number of parameters (also called features or variables), but this is NOT true for top level experiments in Deep Neural Networks, where we work with parameters but only with a pool of examples, but for DNN the Regularization tecniche is NOT used.
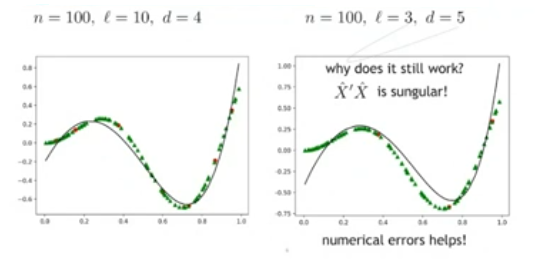
Extension of the Information Matrix
Continuing using the linear regression, we can extend the Information Matrix with some non-linear terms.
We can add a column that consist of all the square elements of the first parameter: . Resulting in:
From the point of view of the algorithm to calculate the weight matrix nothing changes, we just need to find one more weight than before.
Regularization Term
Often to compensate after extending the matrix, or for compensate on overfitting, we introduce a regularization term, so we add to the cost function the term :
So when calculating the cost, we can impose that the weights do not assume too high values.
IDEA: The regularization term can be think about a flatting term, augmenting the resulting plot will be more flat.
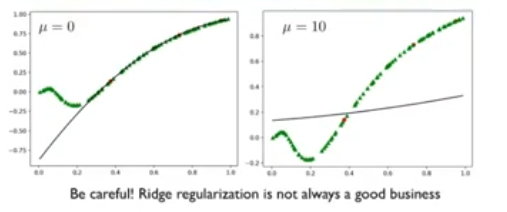
~Ex.: Solution even with